How to Enhance Machine Vision Systems with Optimization Tools

Model optimization tools are essential for enhancing the performance of a machine vision system, which is crucial for automating tasks like object detection and quality control. These systems often encounter challenges such as high latency, excessive memory consumption, and hardware limitations. By leveraging model optimization tools, these issues can be addressed through improved speed, accuracy, and efficiency. For instance, optimized models can decrease processing time by up to 1.347x and reduce memory usage by as much as 48%. These tools help overcome hardware constraints, enabling faster inference and superior performance, ensuring that a machine vision system functions effectively in real-world applications.
Key Takeaways
- Optimization tools make machine vision systems faster, more accurate, and efficient. They solve problems like delays and high memory use.
- Methods like quantization and pruning shrink model size and lower computing needs. This makes them great for real-time tasks on small devices.
- Improving machine vision systems gives big advantages, like quicker processing and lower costs. This helps industries such as factories and healthcare.
- Picking the right method depends on your hardware and needs. This ensures the best performance for your task.
- Trying tools like TensorFlow Lite and OpenVINO can improve your machine vision systems. This leads to better results.
Understanding Machine Vision Systems
What Are Machine Vision Systems
Machine vision systems are advanced technologies that enable machines to "see" and interpret visual data. These systems use cameras, sensors, and software to capture and analyze images or videos. By mimicking human vision, they perform tasks like object detection, quality inspection, and pattern recognition. Unlike human vision, these systems can process vast amounts of data with precision and speed, making them indispensable in industries like manufacturing, healthcare, and agriculture.
Core Components of Machine Vision Systems
A machine vision system relies on several critical components to function effectively. These include:
- Imaging hardware: Cameras and sensors capture high-quality images.
- Lighting and optics: Proper lighting ensures clear image formation, while lenses focus on the target.
- Processing units: These units analyze visual data using algorithms and deep learning models.
- Software: The software drives the system, enabling tasks like object detection and decision-making.
The design and specification of imaging components including sensors, lighting, optics, and computing platforms relative to the needs of the application is critical to the success of the entire system. There is no shortcut in software that will make up for incorrect image formation or lack of processing speed or power.
While the hardware components that perform the tasks of image formation, acquisition, component control, and interfacing are decidedly critical to the solution, machine vision software is the engine 'under the hood' that supports and drives the imaging, processing, and ultimately the results.
Common Applications of Machine Vision Systems
Machine vision systems are transforming industries by enhancing efficiency and accuracy. Some of their most common applications include:
-
Manufacturing: Real-time quality control and defect detection improve production standards.
-
Healthcare: Advanced imaging systems assist in diagnostics and surgical procedures.
-
Automotive: Autonomous vehicles rely on these systems for navigation and safety.
-
Agriculture: Precision farming uses machine vision to monitor crops and optimize yields.
-
The machine vision market is expanding due to increasing automation demands across various industries.
-
Machine vision systems enhance efficiency, accuracy, and productivity by providing real-time visual inspection and quality control.
-
Advancements in AI and automation are improving precision and efficiency in sectors like manufacturing and healthcare.
These applications highlight the versatility and growing importance of machine vision systems in modern technology.
Why Model Optimization Is Crucial for Machine Vision
Challenges in Machine Vision Systems (Latency, Memory, Hardware Constraints)
Machine vision systems face several challenges that can hinder their performance. Latency, or the delay in processing visual data, often affects real-time predictions. High memory consumption can limit the scalability of these systems, especially when deployed on edge devices. Hardware constraints, such as limited computational power, further complicate the implementation of deep learning models.
These challenges arise due to the complexity of tasks like real-time image processing and the need for fast performance. For example, analyzing high-resolution images requires significant computational resources, which can lead to bottlenecks in latency reduction. Addressing these issues is essential for ensuring that machine vision systems operate efficiently in demanding environments.
The Role of Model Optimization in Addressing These Challenges
Model optimization plays a vital role in overcoming the inherent challenges of machine vision systems. By optimizing machine vision systems, you can reduce latency, minimize memory usage, and adapt models to hardware constraints. Several techniques contribute to this process:
- Quantization reduces the precision of numbers in neural networks, decreasing model size and improving speed and energy efficiency.
- Pruning eliminates redundant weights in neural networks, enhancing performance by removing unnecessary connections.
- Fine-tuning adjusts pre-trained models to specific tasks, ensuring efficiency while maintaining accuracy.
These techniques enable real-time model optimization, allowing machine vision systems to deliver fast performance and real-time predictions. For instance, quantization can significantly reduce latency, making it ideal for applications requiring real-time image processing.
Tip: Evaluating AI model optimization techniques based on your hardware and application needs can help you achieve the best results.
Benefits of Optimizing Machine Vision Systems: Speed, Accuracy, and Efficiency
Optimizing machine vision systems offers measurable benefits that enhance their overall performance. Improved speed and accuracy allow these systems to process visual data faster and with greater precision. For example, optimized systems achieve over 99% accuracy in identifying defects, outperforming manual inspections.
Efficiency gains are equally significant. Manufacturers report a 25% reduction in downtime due to real-time inspections, which boosts operational productivity. Long-term cost savings also result from reduced waste and lower rework rates. These benefits highlight the importance of model performance optimization in achieving superior results.
By focusing on model performance enhancement, you can unlock the full potential of machine vision systems. Whether you're working with deep learning models or evaluating AI model optimization techniques, the right approach ensures that your system delivers fast performance and reliable real-time predictions.
Key Techniques for AI Model Optimization in Machine Vision
Quantization: Reducing Model Precision for Faster Inference
Quantization is one of the most effective techniques for optimizing machine vision systems. It reduces the precision of numerical values in deep learning models, such as weights and activations, from 32-bit floating-point numbers to lower-precision formats like 8-bit integers. This reduction significantly decreases the computational load, enabling faster inference and lower energy consumption.
When you apply quantization, your machine vision system can process visual data more efficiently, especially on edge devices with limited hardware resources. For example, quantized models often achieve comparable accuracy to their full-precision counterparts while reducing latency by up to 50%. This makes quantization ideal for applications requiring real-time predictions, such as autonomous vehicles or industrial automation.
Tip: Quantization works best when paired with high-quality training data to ensure minimal loss in speed and accuracy during inference.
Pruning: Removing Redundant Parameters to Reduce Model Size
Pruning focuses on eliminating unnecessary parameters in deep learning models. By removing redundant weights and biases, you can achieve significant size reduction without compromising model performance. This technique is particularly useful for optimizing machine vision systems deployed on devices with limited memory and computational power.
Pruning enhances speed and accuracy by simplifying the model architecture. For instance, pruning can reduce the size of a neural network by up to 90%, enabling faster inference and lower memory usage. You can implement pruning during or after training, depending on your optimization goals.
Several advanced algorithms, such as L1/L2 regularization, support pruning by penalizing large weights and biases. These methods ensure that your machine vision system focuses on the most relevant features, improving efficiency and accuracy.
Callout: Early stopping during training can complement pruning by preventing overfitting and ensuring optimal model performance enhancement.
Clustering: Grouping Weights for Efficient Computation
Clustering is another powerful technique for optimizing deep learning models in machine vision systems. It groups similar weights in a neural network, reducing the complexity of computations during inference. This approach improves speed and accuracy while maintaining the integrity of the model's predictions.
When you use clustering, your machine vision system benefits from reduced memory usage and faster processing times. For example, clustering can compress model size by grouping weights into fewer representative values, enabling efficient computation on edge devices.
Bayesian optimization, an advanced algorithm, can further enhance clustering by modeling the relationship between hyperparameters and evaluation metrics. This ensures that your machine vision system achieves optimal performance with minimal computational overhead.
Note: Combining clustering with techniques like dropout can promote diverse representations of input data, further improving model accuracy.
Knowledge Distillation: Transferring Knowledge from Large Models to Smaller Ones
Knowledge distillation is a powerful technique for optimizing machine vision systems. It involves transferring the knowledge and capabilities of large, complex models (teachers) to smaller, more efficient models (students). This process allows you to retain the performance of the original model while reducing computational demands, making it ideal for deployment on edge devices or hardware with limited resources.
Large teacher models generate synthetic training data that enhances the learning process of smaller models. This synthetic data can be tailored to specific tasks, such as legal reasoning or mathematical problem-solving, ensuring that the student model excels in its domain. By integrating knowledge distillation during pre-training, you can reduce training time and resource consumption while improving generalization across tasks.
| Technique | Description |
|---|---|
| Teacher-Generated Synthetic Data | Large teacher models create synthetic training examples, enhancing the training of smaller models. |
| Task-Specific Synthesis | Customizing synthetic data for specific domains improves performance in tasks like mathematics and legal reasoning. |
| Efficiency in Large-Scale Training | Integrating knowledge distillation during pre-training reduces training time and resource consumption. |
| Iterative Pre-Training with Distillation | Teacher models guide the pre-training of smaller models, improving their generalization across tasks. |
| Few-Shot Distillation | Distillation with minimal labeled examples allows models to perform well on new or underrepresented tasks. |
| Zero-Shot KD | Students inherit zero-shot generalization capabilities from teachers, as seen in frameworks like TinyLLM and DeepSeek-R1. |
This technique also supports few-shot and zero-shot learning, enabling smaller models to perform well on new or underrepresented tasks. For example, frameworks like TinyLLM demonstrate how student models inherit zero-shot generalization capabilities from their teacher models.
Tip: To maximize the benefits of knowledge distillation, ensure high-quality training data and select teacher models that align with your application needs.
Hyperparameter Tuning: Fine-Tuning Models for Optimal Performance
Hyperparameter tuning is essential for optimizing machine vision systems. It involves adjusting the parameters that control the behavior of deep learning models, such as learning rate, batch size, and the number of layers. By fine-tuning these hyperparameters, you can achieve significant improvements in speed and accuracy.
When you optimize model hyperparameters, you enhance the performance of your machine vision system on benchmark datasets like CIFAR-10. Studies show that hyperparameter tuning can lead to a 4–6% improvement in accuracy, which is critical for applications requiring precise visual data analysis.
- Learning Rate: Determines how quickly the model updates its weights during training. A well-tuned learning rate prevents overfitting and ensures faster convergence.
- Batch Size: Controls the number of training samples processed at once. Smaller batch sizes improve generalization, while larger ones speed up training.
- Number of Layers: Balances model complexity and computational efficiency. Adjusting layers ensures optimal performance without excessive resource usage.
Hyperparameter optimization relies on advanced algorithms like Bayesian optimization and grid search. These methods systematically explore the hyperparameter space to identify the best configuration for your machine vision system.
Note: High-quality training data plays a crucial role in hyperparameter tuning. Ensure your dataset is diverse and representative to achieve reliable results.
By focusing on hyperparameter tuning, you can unlock the full potential of deep learning optimization. This process not only enhances speed and accuracy but also ensures your machine vision system operates efficiently in real-world scenarios.
Tools and Frameworks for Model Optimization in Machine Vision Systems
TensorFlow Lite: Lightweight Models for Mobile and Edge Devices
TensorFlow Lite (TFLite) is a versatile tool designed to optimize machine vision systems for mobile and edge devices. It supports techniques like quantization, pruning, and weight clustering, which reduce model size and improve inference speed. These features make TFLite ideal for applications requiring inference at the edge, such as real-time object detection on smartphones or IoT devices.
Benchmarking results highlight TFLite's efficiency. For instance, a quantized Mobilenet_1.0_224 model achieves a processing time of just 5 milliseconds on a Pixel 4 CPU. This performance demonstrates how TFLite enables faster and more efficient machine vision systems on constrained hardware.
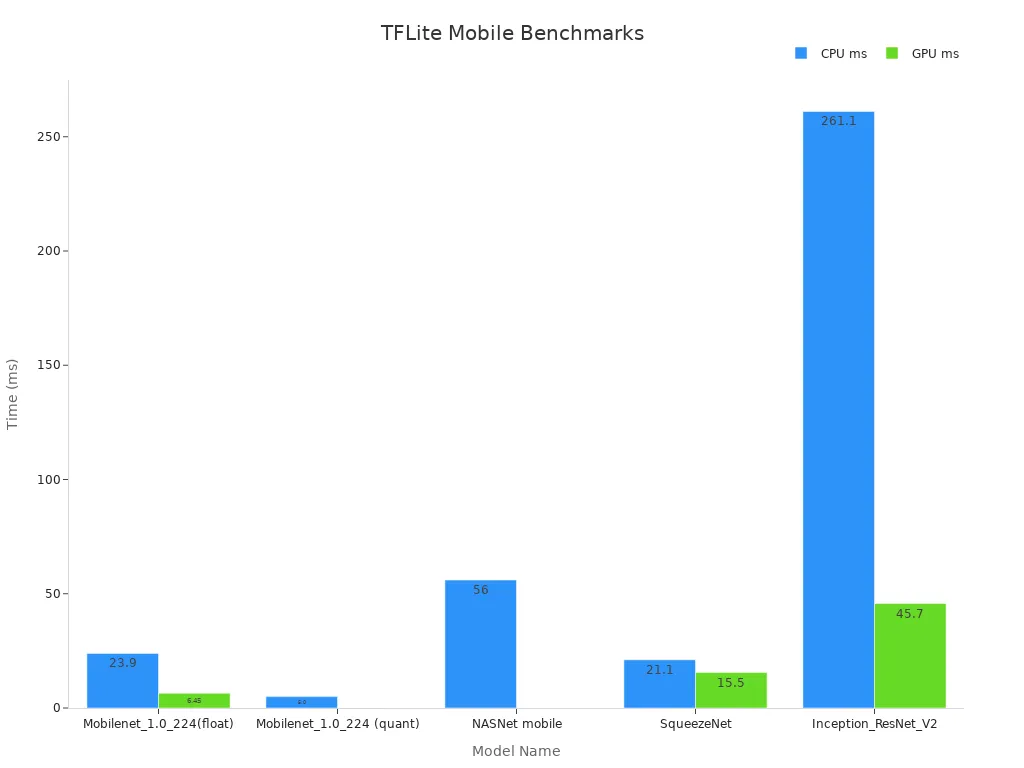
Tip: Use TFLite for applications where low latency and energy efficiency are critical, such as wearable devices or autonomous drones.
TensorRT: High-Performance Inference for NVIDIA GPUs
TensorRT is a powerful framework that accelerates inference for machine vision systems on NVIDIA GPUs. It offers system-specific optimizations, such as layer fusion and precision calibration, to maximize throughput and minimize latency. This makes TensorRT a go-to choice for real-time applications like video analytics and autonomous vehicles.
Performance benchmarks underscore TensorRT's capabilities. For example, the Llama 4 Scout model achieves a throughput of 40,000 tokens per second, delivering a 3.4x speed improvement. These results highlight TensorRT's ability to handle demanding workloads efficiently.
Callout: TensorRT excels in scenarios requiring high-performance inference at the edge, especially when paired with NVIDIA hardware.
OpenVINO: Optimizing Models for Intel Hardware
OpenVINO (Open Visual Inference and Neural Network Optimization) is an advanced optimization tool tailored for Intel hardware. It simplifies the deployment of machine vision systems by optimizing models for CPUs, GPUs, and VPUs. OpenVINO supports a wide range of deep learning frameworks, ensuring compatibility and flexibility.
This framework excels in applications like industrial automation and healthcare imaging. By leveraging OpenVINO, you can achieve faster inference at the edge while maintaining high accuracy. Its support for standardized datasets like ImageNet ensures reliable benchmarking and performance evaluation.
Note: OpenVINO's versatility makes it a strong candidate for optimizing machine vision systems across diverse hardware platforms.
ONNX Runtime: Cross-Platform Optimization for Machine Learning Models
ONNX Runtime is a versatile framework designed to optimize machine vision systems across multiple platforms. It supports a wide range of hardware, including CPUs, GPUs, and specialized accelerators. This flexibility makes it an excellent choice for deploying models in diverse environments. By using ONNX Runtime, you can achieve faster inference at the edge without sacrificing accuracy.
One of the key features of ONNX Runtime is its ability to integrate with various deep learning frameworks. Whether you use PyTorch, TensorFlow, or another platform, ONNX Runtime ensures seamless model conversion and deployment. This cross-platform compatibility simplifies the optimization process, allowing you to focus on improving performance.
ONNX Runtime also includes advanced optimization tools like graph optimization and operator fusion. These tools streamline computations, reducing latency and improving efficiency. For example, graph optimization eliminates redundant operations, while operator fusion combines multiple operations into a single step. These enhancements enable your machine vision systems to process data more quickly and efficiently.
Tip: Use ONNX Runtime for applications requiring high-speed inference at the edge, such as real-time video analytics or object detection.
PyTorch Mobile: Optimizing Models for Mobile Applications
PyTorch Mobile is a powerful tool for optimizing machine vision systems on mobile devices. It allows you to deploy deep learning models directly on smartphones, tablets, and other portable devices. This capability is crucial for applications like augmented reality and mobile health monitoring, where real-time processing is essential.
With PyTorch Mobile, you can perform inference at the edge, reducing the need for cloud-based processing. This approach minimizes latency and enhances user privacy by keeping data on the device. PyTorch Mobile also supports quantization, which reduces model size and speeds up inference. These features make it ideal for resource-constrained environments.
Another advantage of PyTorch Mobile is its ease of use. You can convert existing PyTorch models into mobile-compatible formats with minimal effort. The framework also provides tools for debugging and performance profiling, helping you fine-tune your models for optimal results.
Callout: PyTorch Mobile is perfect for developers looking to bring advanced optimization tools to mobile applications, ensuring efficient and accurate machine vision systems.
Choosing the Right Optimization Techniques for Machine Vision Systems
Factors to Consider: Hardware, Application Needs, and Constraints
When selecting optimization techniques for machine vision systems, you need to evaluate several factors. Hardware specifications play a critical role. Devices with limited computational power, such as edge devices, require lightweight models. On the other hand, cloud systems can handle larger models due to their robust infrastructure.
Application needs also influence your choice. Real-time applications, like autonomous vehicles, demand low-latency solutions. In contrast, tasks like medical imaging may prioritize accuracy over speed. Constraints, such as memory availability and energy consumption, further shape your decisions.
The table below highlights key metrics to consider when aligning optimization techniques with hardware and application demands:
| Metric | Description |
|---|---|
| CPU Utilization | Measures the usage of CPU resources. |
| Memory Utilization | Gauges the usage of memory resources. |
| Disk I/O | Assesses the performance of storage systems. |
| Network Latency | Indicates the time taken for data to travel. |
| Throughput | Reflects the capacity of the network. |
| Availability | Denotes the operational uptime of the system. |
| Reliability | Ensures functionality without errors. |
| Quality | Signifies user satisfaction with the system. |
By analyzing these metrics, you can identify the best optimization strategies for your machine vision systems.
Matching Techniques to Use Cases: Edge Devices vs. Cloud Systems
Matching optimization techniques to specific use cases ensures your machine vision systems perform efficiently. For edge devices, techniques like quantization and pruning are ideal. These methods reduce model size and computational requirements, enabling real-time predictions on hardware with limited resources.
For cloud systems, you can leverage more powerful optimization strategies. These include techniques that minimize data transfer delays and improve inference speed. Cloud deployment allows you to use larger models, but optimizing for network latency remains essential.
- Edge devices benefit from real-time predictions and enhanced data security but face hardware constraints.
- Cloud systems support larger models and higher computational loads but may encounter delays in data transfer.
By aligning techniques with your deployment environment, you can maximize the performance of your machine vision systems.
Balancing Trade-offs: Accuracy vs. Speed vs. Resource Usage
Optimization often involves trade-offs between accuracy, speed, and resource usage. You must decide which factor takes priority based on your application. For instance, in industrial automation, speed may outweigh accuracy to maintain production efficiency. Conversely, in healthcare, accuracy is paramount, even if it increases latency.
Resource usage also impacts your choices. Lightweight models consume less memory and energy, making them suitable for edge devices. However, these models may sacrifice some accuracy. Striking the right balance ensures your machine vision systems meet both performance and operational goals.
Tip: Start with a baseline model and iteratively apply optimization techniques. This approach helps you evaluate trade-offs effectively while maintaining system reliability.
Real-World Applications of Optimizing Machine Vision Systems

Optimized Machine Vision in Autonomous Vehicles
Autonomous vehicles rely heavily on machine vision systems to navigate safely and efficiently. These systems use object detection to identify pedestrians, vehicles, and road signs. Optimizing machine vision systems ensures faster decision-making, which is critical for real-time image processing. For example, model optimization tools in a machine vision system can reduce latency, enabling vehicles to respond to obstacles in milliseconds.
Quantization and pruning are common techniques used in this field. They help reduce the size of deep learning models, making them suitable for deployment on edge devices like in-vehicle processors. This optimization improves both speed and energy efficiency, ensuring that autonomous vehicles operate reliably in dynamic environments.
Tip: When designing machine vision systems for autonomous vehicles, prioritize techniques that enhance speed without compromising accuracy.
Applications in Industrial Automation and Quality Control
In manufacturing, quality control is a top priority. Machine vision systems play a vital role in inspecting products for defects. By optimizing machine vision systems, you can achieve higher accuracy and faster inspections. For instance, a global electronics manufacturer implemented a machine vision system to analyze circuit boards. This system improved the defect detection rate by 25%, reducing faulty products and enhancing customer satisfaction.
Model optimization tools in a machine vision system also enable real-time image processing, which is essential for assembly lines. Techniques like clustering and knowledge distillation make these systems more efficient, even on hardware with limited resources. As a result, manufacturers can maintain high production standards while minimizing downtime.
Callout: Optimizing machine vision systems for quality control not only improves accuracy but also reduces operational costs.
Enhancing Medical Imaging with Optimized Models
Medical imaging has seen significant advancements with the integration of machine vision systems. These systems assist in diagnosing diseases by analyzing X-rays, MRIs, and CT scans. Optimizing machine vision systems ensures faster and more accurate image analysis, which is crucial for early detection and treatment.
For example, model optimization tools in a machine vision system can reduce the size of neural networks, enabling deployment on portable medical devices. This allows healthcare professionals to perform diagnostics in remote areas. Techniques like hyperparameter tuning further enhance the accuracy of these systems, ensuring reliable results.
Note: In medical imaging, prioritize accuracy when optimizing machine vision systems to ensure patient safety and effective diagnoses.
Model optimization tools transform machine vision systems by enhancing speed, accuracy, and efficiency. These tools help you overcome challenges like latency and hardware limitations, ensuring reliable performance in real-world applications.
Tip: Always evaluate your hardware and application needs before selecting optimization techniques.
Experimenting with tools like TensorFlow Lite or OpenVINO allows you to unlock the full potential of your systems. By exploring these options, you can create solutions tailored to your specific requirements. Start optimizing today to achieve superior results in your machine vision projects!
FAQ
What is the main purpose of optimizing machine vision systems?
Optimization improves speed, accuracy, and efficiency. It helps reduce latency, memory usage, and computational demands. This ensures your system performs well in real-world applications, even on hardware with limited resources.
Which optimization technique is best for edge devices?
Quantization works best for edge devices. It reduces model size and computational load, enabling faster inference. This makes it ideal for real-time applications like object detection on mobile or IoT devices.
Can optimization reduce accuracy in machine vision systems?
Some techniques, like quantization, may slightly reduce accuracy. However, careful implementation and high-quality training data minimize this impact. You can balance trade-offs to maintain acceptable accuracy levels while improving speed and efficiency.
How do I choose the right optimization tool for my project?
Consider your hardware, application needs, and constraints. For example, TensorFlow Lite suits mobile devices, while TensorRT excels with NVIDIA GPUs. Match the tool to your system's requirements for the best results.
Are optimization techniques difficult to implement?
Many tools, like TensorFlow Lite and OpenVINO, simplify the process. They offer user-friendly interfaces and pre-built functions. With basic knowledge of machine learning frameworks, you can start optimizing your models effectively.
Tip: Start with small changes and test their impact to build confidence in using optimization techniques.
See Also
Investigating Synthetic Data's Role In Machine Vision Innovation
The Impact of Deep Learning On Machine Vision Performance
Does Filtering Improve Accuracy In Machine Vision Systems?
Essential Image Processing Libraries For Machine Vision Excellence