How Feature Extraction Powers Machine Vision Systems

Feature extraction plays a crucial role in helping machines interpret visual data. By identifying key patterns and converting raw images into actionable information, it serves as the backbone of many technologies. For instance, a feature extraction machine vision system leverages this process to analyze images, detect objects, and recognize shapes. This significantly reduces data complexity, allowing for faster and more precise digital image processing.
The influence of feature extraction machine vision systems is evident across various industries. The global machine vision market is experiencing rapid growth, with hardware accounting for 61% of the market share in 2024. Meanwhile, software solutions are projected to grow at a CAGR of 13% from 2025 to 2030, fueled by the increasing demand for automation and advanced image segmentation.
Key Takeaways
- Feature extraction makes hard visual data simpler. This helps machines find important patterns and understand images better.
- Deep learning tools, like Convolutional Neural Networks (CNNs), improve feature extraction. They find tricky patterns on their own, making tasks like face recognition and medical scans more accurate.
- By simplifying data, feature extraction speeds up computing and improves machine learning models. This makes them work better in real-life tasks.
Understanding Feature Extraction in Machine Vision Systems
What Is Feature Extraction?
Feature extraction is the process of identifying and isolating key characteristics from raw image data. It transforms complex visual information into simpler, structured data that machines can analyze. For example, when analyzing an image, feature extraction focuses on elements like edges, shapes, textures, and colors. These features help machines understand the image's content without processing every pixel.
You can think of feature extraction as a translator between raw image data and actionable insights. It bridges the gap by converting visual information into numerical features. Techniques like autoencoders and principal component analysis (PCA) are commonly used to achieve this. Autoencoders learn to identify significant features by recreating input data, while PCA reduces dimensionality while preserving essential information. These methods ensure that the extracted features retain the most critical details for analysis.
In machine vision systems, feature extraction plays a foundational role. It enables tasks like image registration, object detection, and content-based image retrieval. By focusing on the most relevant aspects of an image, feature extraction simplifies the data, making it easier for machines to process and interpret.
Why Is Feature Extraction Important in Machine Vision?
Feature extraction is essential for machine vision because it allows systems to interpret visual data accurately and efficiently. Without it, machines would struggle to process the vast amount of information in raw images. By isolating key features, feature extraction enables tasks like object recognition, image segmentation, and classification.
Here’s how feature extraction transforms raw image data into actionable insights:
- Preprocessing: It cleans the image by removing noise and enhancing quality.
- Feature Extraction: It identifies patterns like edges, shapes, and textures.
- Segmentation: It divides the image into segments to isolate areas of interest.
- Object Recognition: It classifies and identifies objects within the image.
- Data Conversion: It converts extracted features into a structured format for analysis.
These steps highlight the importance of feature extraction in computer vision. For instance, advancements in YOLOv11's feature extraction modules have significantly improved its ability to detect small targets. This has increased detection confidence and reduced errors, demonstrating the critical role of feature extraction in achieving accurate object detection.
How Feature Extraction Reduces Data Complexity
Feature extraction simplifies data by focusing on the most relevant information. This reduction in complexity makes it easier for machines to process and analyze visual data. Instead of analyzing every pixel, feature extraction methods like SIFT and HOG identify key points and patterns, streamlining the process.
The benefits of feature extraction in reducing data complexity include:
| Benefit | Explanation |
|---|---|
| Reduced Computation Cost | Simplifies data by focusing on vital information, making it easier for machines to process. |
| Improved Model Performance | Key features provide insights into data processes, enhancing model accuracy. |
| Better Insights | Algorithms perform better with fewer features, reducing noise and focusing on significant data. |
| Overfitting Prevention | Simplifies models to prevent overfitting, improving generalization to new data. |
By reducing data complexity, feature extraction not only improves computational efficiency but also enhances the accuracy of machine learning models. This is particularly important in applications like image processing, where large datasets can overwhelm systems. Effective feature extraction ensures that only the most critical information is retained, enabling faster and more accurate data analysis.
Techniques for Feature Extraction in Machine Vision

Traditional Methods: Edge Detection and SIFT
Traditional feature extraction methods have been the foundation of computer vision for decades. These techniques focus on identifying specific patterns in images, such as edges, corners, and textures, to simplify image data extraction. Two widely used methods in this category are edge detection and the scale-invariant feature transform (SIFT).
Edge detection is one of the simplest yet most effective image processing techniques. It identifies boundaries within an image by detecting sharp changes in brightness. For example, the Sobel and Canny edge detection algorithms are popular for their ability to highlight object outlines. This makes them ideal for tasks like object detection and image segmentation.
SIFT, on the other hand, is a more advanced method. It detects and describes local features in images, making it robust to changes in scale, rotation, and lighting. This scale-invariant feature transform is particularly useful for image feature detection in applications like image stitching and 3D reconstruction.
Tip: While traditional methods like edge detection and SIFT are reliable, they may struggle with complex datasets or images containing hidden patterns.
Advanced Techniques: Deep Learning-Based Feature Extraction
Deep learning has revolutionized feature extraction by enabling machines to learn features directly from raw image data. Unlike traditional methods, which rely on predefined rules, deep learning-based approaches use neural networks to automatically identify patterns and relationships within images.
Convolutional Neural Networks (CNNs) are at the heart of this transformation. These networks excel at extracting hierarchical features, starting with simple edges and progressing to complex shapes and objects. For instance, CNNs power modern applications like facial recognition, medical imaging, and autonomous vehicles.
A comparison of traditional and deep learning-based feature extraction methods highlights their strengths and weaknesses:
| Method Type | Strengths | Weaknesses |
|---|---|---|
| Traditional | Established and reliable | Struggles with deep hidden features |
| Deep Learning | High accuracy and adaptability | Limited by small sample sizes |
Deep learning-based feature extraction methods also outperform classical approaches in non-linear scenarios. However, they require large datasets and significant computational resources.
| Method Type | Performance | Comments |
|---|---|---|
| DL-based FS | Varies | Shows potential but needs improvement |
| Classical FS | Unsuitable | Fails to extract relevant features in non-linear scenarios |
When applied correctly, deep learning offers unparalleled accuracy and efficiency in image processing. It represents the future of feature extraction machine vision systems.
Other Common Approaches: HOG and Texture Analysis
In addition to traditional and deep learning-based methods, other feature extraction techniques like the histogram of oriented gradients (HOG) and texture analysis play a significant role in computer vision.
HOG focuses on capturing the structure and appearance of objects by analyzing the distribution of gradient directions in an image. This method is particularly effective for detecting objects like pedestrians and vehicles. For example, HOG has been widely used in surveillance systems and autonomous navigation.
Texture analysis, on the other hand, examines the surface properties of objects. It identifies patterns such as smoothness, roughness, or regularity. Combining HOG with texture analysis often yields superior results. A study comparing HOG and local binary patterns (LBP) for classifying small metal objects found that HOG outperformed LBP. When combined, the two methods achieved even better accuracy.
Note: HOG and texture analysis are especially useful for applications requiring high precision, such as industrial quality control and medical imaging.
These feature extraction methods demonstrate the benefits of feature extraction in simplifying data analysis and improving model performance. By leveraging techniques like HOG and texture analysis, you can enhance the accuracy and efficiency of your machine learning models.
Applications of Feature Extraction in Machine Vision Systems
Facial Recognition and Security Systems
Feature extraction plays a vital role in facial recognition systems, enabling accurate identification even in challenging conditions. By analyzing unique facial features like the distance between eyes or the shape of the jawline, these systems can match faces to stored profiles. This technology is widely used in security systems for access control and surveillance.
The accuracy of facial recognition depends on factors like lighting and dataset size. For instance, systems trained with 500 images per individual achieve up to 93% accuracy under normal lighting. However, accuracy drops significantly when masks are worn, especially in low-light conditions.
| Condition | 30 Images/Member | 500 Images/Member |
|---|---|---|
| Normal Lighting | 79% | 93% |
| Low Lighting | 72% | 88% |
| Wearing a Mask (Normal Lighting) | 65% | 75% |
| Wearing a Mask (Low Lighting) | 41% | 56% |
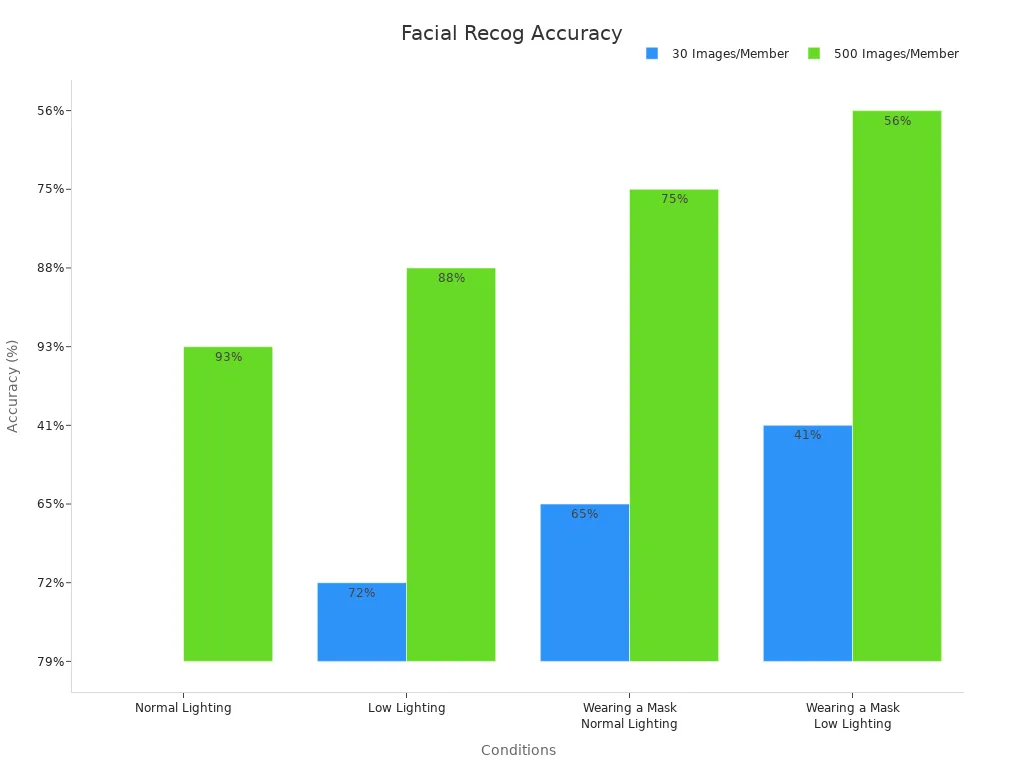
Larger datasets and better lighting conditions improve performance. You can see how feature extraction enhances the reliability of these systems, making them indispensable in modern security applications.
Medical Imaging and Diagnostics
In medical imaging, feature extraction helps identify patterns that may indicate diseases. For example, it can detect abnormalities in X-rays or MRI scans by focusing on specific image features like texture or shape. This allows doctors to diagnose conditions more accurately and quickly.
Deep learning-based systems, powered by convolutional neural networks (CNNs), have revolutionized this field. These systems excel at detecting subtle differences in medical images, such as cosmetic flaws or early signs of cancer. However, they require extensive training with diverse datasets to handle variations in patient data.
Implementing a deep learning system involves training convolutional neural networks (CNN) on data that makes it easier to deal with ambiguous or difficult characterizations, such as detecting cosmetic flaws. Systems often require a large amount of sample images to capture part variation for accurate results and to reduce false negatives.
With detection efficiency reaching 97.88% and accuracy at 88.75%, feature extraction has become a cornerstone of modern medical diagnostics. It not only improves patient outcomes but also streamlines the diagnostic process.
Autonomous Vehicles and Navigation
Autonomous vehicles rely heavily on feature extraction to navigate safely. By analyzing visual data from cameras and sensors, these systems identify objects like pedestrians, road signs, and other vehicles. This enables real-time decision-making and ensures safe navigation.
Techniques like the histogram of oriented gradients (HOG) and deep learning-based methods are commonly used in these systems. HOG captures the structure of objects, while deep learning models adapt to complex scenarios like varying weather conditions.
Feature extraction simplifies image processing by focusing on critical details, such as lane markings or obstacles. This reduces computational demands and enhances the vehicle's ability to react quickly. As a result, autonomous vehicles can operate efficiently in diverse environments, bringing us closer to a future of safer, smarter transportation.
Challenges in Feature Extraction Machine Vision System
Variability in Image Quality and Lighting
Image quality and lighting conditions often vary significantly, creating challenges for feature extraction. You might encounter scenarios where images are blurry, poorly lit, or overexposed. These inconsistencies make it harder for machine vision systems to identify key features accurately. For example, a study comparing single-stream spatial models with multi-stream spatiotemporal models found that incorporating a temporal stream improves robustness against input changes. Training with video data enhances resilience to dynamic variations in image quality and lighting, making models more adaptable to real-world conditions. This highlights the importance of designing systems that can handle unpredictable visual inputs effectively.
Computational Demands and Resource Constraints
Feature extraction methods often require substantial computational resources, especially when dealing with large datasets or complex algorithms. You might notice that some models, like convolutional neural networks (CNNs), are more compact and efficient. CNNs utilize memory effectively, making them suitable for environments with limited resources. On the other hand, Vision Transformers demand higher memory and computational power due to their larger model sizes.
- Model Size: CNNs are smaller and more resource-efficient.
- Memory Requirements: CNNs outperform Vision Transformers in memory usage.
- Training Efficiency: CNNs excel in image processing tasks, while Vision Transformers require more resources for larger datasets.
Understanding these benchmarks helps you choose the right feature extraction approach based on your system's resource availability.
Balancing Accuracy with Efficiency
Achieving a balance between accuracy and computational efficiency is crucial in feature extraction. You might find that machine learning models like logistic regression and random forests perform comparably to deep learning models on medium-sized datasets. While ML models offer better interpretability and require fewer resources, DL models excel at identifying complex patterns in larger datasets.
Metrics like accuracy, precision, recall, and F1 score help you evaluate this trade-off. For smaller datasets, ML models may be more efficient, while DL models shine in scenarios requiring high accuracy and complexity. By carefully assessing your application's needs, you can strike the right balance between performance and resource usage.
Feature extraction forms the backbone of machine vision systems, enabling precise visual data interpretation. Recent innovations address challenges like computational demands and image variability:
- Real-time processing ensures quick analysis of large datasets.
- Automated labeling tools reduce manual effort.
- Deep learning enhances image recognition accuracy.
| Trend | Description |
|---|---|
| Deep Learning Integration | AI models are improving in automatically extracting features without human input. |
| Hybrid Approaches | Merging traditional feature engineering with deep learning for better accuracy and efficiency. |
| AutoML for Feature Selection | Automated feature extraction is now part of machine learning platforms, simplifying workflows for data scientists. |
The future of feature extraction lies in AI integration, promising smarter, human-like visual data processing.
FAQ
What is the role of feature extraction in machine vision?
Feature extraction simplifies raw image data into meaningful patterns. This helps machines identify objects, shapes, and textures for tasks like recognition and detection.
How does deep learning improve feature extraction?
Deep learning automates feature identification by analyzing raw data. Neural networks, like CNNs, detect complex patterns, improving accuracy in applications such as facial recognition and medical imaging.
Can feature extraction handle poor-quality images?
Yes, but with limitations. Advanced techniques, like multi-stream models, improve robustness against low-quality images by incorporating temporal data and enhancing adaptability to varying conditions.
See Also
Understanding Camera Resolution in Machine Vision Applications
Essential Insights Into Computer Vision Versus Machine Vision
Exploring How Synthetic Data Enhances Machine Vision Capabilities
Utilizing Machine Vision Technologies in Food Manufacturing Processes