What Are Few-Shot and Active Learning Techniques in Machine Vision

Few-shot learning and active learning are transformative approaches in the realm of machine vision systems. Few-shot learning enables the training of models with minimal labeled data, allowing machines to generalize effectively from just a few examples. This method is particularly impactful in areas like medical imaging, where labeled data is often limited. For example, a study leveraging a few-shot learning and active learning machine vision system achieved a 14% improvement in periodontal disease classification compared to traditional models, even with only 100 labeled images.
Active learning complements this by emphasizing efficiency. It focuses on selecting the most valuable data for labeling, ensuring that only the most insightful data is prioritized instead of labeling everything. When combined, few-shot learning and active learning create a robust machine vision system that addresses data scarcity while significantly enhancing model performance.
Key Takeaways
- Few-shot learning helps models learn from a small number of examples. It works well when there isn’t much data, like in medical imaging.
- Active learning saves time by picking the most useful data to label. This lowers the cost and effort needed for labeling.
- Using both few-shot and active learning makes models work better. It helps systems handle new tasks even with little data.
- Methods like Prototypical Networks and Uncertainty Sampling are useful tools. They improve how machine vision systems perform.
- These techniques are helpful in areas like medical imaging, robots, and self-driving cars. They can be used by small businesses and big projects too.
Understanding Few-Shot Learning
What Is Few-Shot Learning?
Few-shot learning is a method that allows machine learning models to perform tasks with very little labeled data. Instead of requiring thousands of examples, you can train a model to generalize from just a few. This approach is especially useful in scenarios where collecting labeled data is expensive or time-consuming, such as medical imaging or rare object detection.
In few-shot classification, the model learns to classify new categories using a small dataset. This dataset is often divided into two parts: the support set and query set. The support set contains a few labeled examples for each class, while the query set includes unlabeled examples that the model needs to classify. By leveraging the support set and query set, the model learns to identify patterns and make predictions even with limited data.
Research studies have shown the effectiveness of few-shot learning in various applications. For instance, one study demonstrated its ability to classify electron backscatter diffraction (EBSD) patterns accurately with fewer labeled examples. Another study highlighted how pretraining techniques enable accurate classification with minimal data. These findings underline the potential of few-shot learning in solving real-world challenges.
How Meta-Learning Powers Few-Shot Learning
Meta-learning, often referred to as "learning to learn," plays a crucial role in enhancing few-shot learning. It focuses on training models to adapt quickly to new tasks by leveraging prior knowledge. Instead of learning a single task, the model learns how to learn multiple tasks efficiently.
For example, in few-shot semantic segmentation, meta-learning techniques have achieved remarkable results. A two-pass end-to-end method significantly improved performance on benchmark datasets like Pascal-5^i and COCO-20^i. On Pascal-5^i, the method boosted accuracy by 2.51% for 1-shot tasks and 1.12% for 5-shot tasks. Similarly, on COCO-20^i, it improved accuracy by 3.98% for 1-shot tasks and 1.6% for 5-shot tasks. These results highlight how meta-learning enables models to adapt and excel in few-shot scenarios.
By incorporating meta-learning, you can build systems that not only perform well with limited data but also generalize effectively to new tasks. This makes it a powerful tool for advancing machine vision technologies.
Key Techniques in Few-Shot Learning
Several techniques have been developed to implement few-shot learning effectively. Two of the most popular methods are Prototypical Networks and Matching Networks.
-
Prototypical Networks: This technique represents each class by a prototype, which is the mean of all feature vectors in the support set. When classifying a query example, the model calculates its distance to each prototype and assigns it to the nearest class. Prototypical Networks are simple yet highly effective, achieving an accuracy of 49.42% in 1-shot classification tasks.
-
Matching Networks: This method uses a different approach by comparing the query example directly with each labeled example in the support set. It employs a similarity function to determine the closest match. Although slightly less accurate than Prototypical Networks, Matching Networks still perform well, with a 1-shot accuracy of 43.56%.
| Technique | 1-shot Accuracy (%) |
|---|---|
| Prototypical Networks | 49.42±0.78 |
| Matching Networks | 43.56±0.84 |
Both techniques demonstrate the potential of few-shot learning in addressing data scarcity. By choosing the right method, you can optimize your machine vision system for specific tasks and achieve impressive results.
Exploring Active Learning
What Is Active Learning?
Active learning is a machine learning technique that focuses on improving model performance by selecting the most informative data points for labeling. Instead of labeling an entire dataset, you prioritize specific samples that provide the most value to the model. This approach reduces the amount of labeled data required while maintaining high accuracy.
Imagine you are training a model to classify images of animals. Instead of labeling thousands of random images, active learning helps you identify the images that will teach the model the most. This strategy saves time and resources, especially when labeling is expensive or time-consuming.
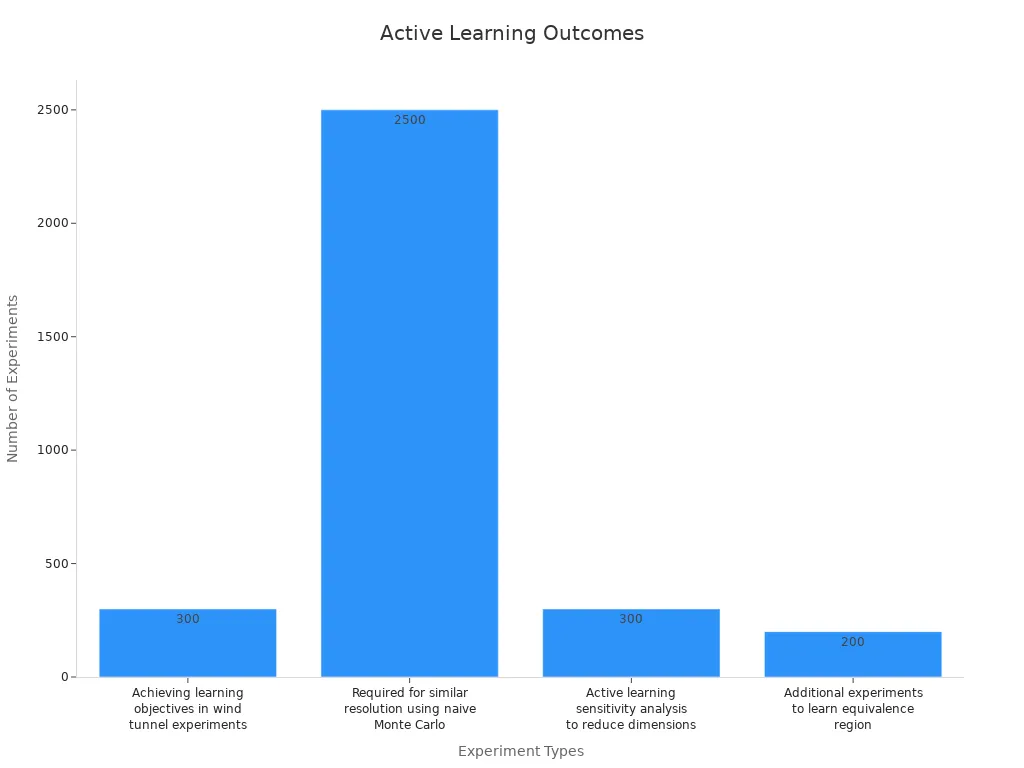
In controlled experiments, active learning has demonstrated remarkable efficiency. For example, in wind tunnel experiments, achieving similar learning objectives with traditional methods required 2,500 experiments. Active learning reduced this number to fewer than 100, representing a 25-fold reduction in effort. The chart below illustrates this comparison:
The Role of Data Selection in Active Learning
Data selection lies at the heart of active learning. By carefully choosing which data points to label, you can maximize the model's learning potential while minimizing costs. However, this process requires a balance. Selecting only the most uncertain or diverse samples can introduce bias, causing the training data to deviate from the true population distribution. Addressing this bias is crucial for achieving optimal results.
One effective solution involves using corrective weights to adjust for this bias. These weights ensure that the selected data remains representative of the overall dataset. This approach is particularly beneficial when training complex models like neural networks with limited data. By mitigating bias, you can enhance the performance of active learning techniques and achieve better outcomes.
Empirical data supports the effectiveness of data selection in active learning. For instance, entropy querying—a method that selects samples with the highest uncertainty—has proven to reduce annotation costs significantly. It also improves the performance of minority classes, narrowing the gap between majority and minority class accuracy. The table below summarizes these findings:
| Finding | Description |
|---|---|
| Entropy Querying | Effectively selects informative samples, reducing annotation costs. |
| Performance Comparison | Outperforms random sampling in most cases. |
| Class Performance | Reduces the performance gap between majority and minority classes. |
Techniques for Active Learning (e.g., Uncertainty Sampling, Query-by-Committee)
Several techniques make active learning a powerful tool for machine vision. Two of the most widely used methods are uncertainty sampling and query-by-committee.
-
Uncertainty Sampling: This technique focuses on selecting data points where the model is least confident. For example, if a model struggles to classify an image as either a cat or a dog, that image becomes a priority for labeling. Uncertainty sampling ensures that the model learns from its most challenging cases, leading to faster improvements. Studies show that epistemic uncertainty sampling, a variant of this method, consistently outperforms standard uncertainty measures like entropy. It also accelerates learning curves, especially for deeper models.
-
Query-by-Committee: This method involves training multiple models (a "committee") on the same dataset. Each model votes on the classification of unlabeled samples. The samples with the most disagreement among the models are selected for labeling. This approach captures diverse perspectives, making it particularly effective for complex tasks. For instance, query-by-committee has shown strong performance across various learning biases, proving its versatility.
The table below highlights the performance gains achieved by these techniques:
| Technique | Performance Gain Description |
|---|---|
| Epistemic Uncertainty Sampling | Shows strong performance and consistently improves on standard uncertainty sampling. |
| Local Learning Methods | Epistemic uncertainty sampling improves upon standard uncertainty measures like entropy. |
| Global Methods | Performs at least on par with standard methods, indicating its viability across different learning biases. |
| Learning Curves | For higher depth limits, learning curves increase faster with epistemic uncertainty, suggesting better performance. |
| Performance Ratio | Epistemic uncertainty tends to be superior, with performance ratios mostly greater than 1 compared to aleatoric. |
By leveraging these techniques, you can build efficient and effective machine vision systems. Active learning not only reduces the need for extensive labeled data but also enhances the model's ability to generalize to new tasks.
Importance of Few-Shot and Active Learning in Machine Vision
Solving the Limited Labeled Data Problem
Few-shot learning and active learning address one of the biggest challenges in machine vision: limited labeled data. You often encounter situations where collecting and labeling data is expensive or impractical. These techniques allow computer vision models to learn effectively from small datasets, making them invaluable for tasks like rare object detection or medical imaging.
Active learning plays a key role by prioritizing the most informative samples for labeling. For example, a simulation study demonstrated that active learning reduced screening time by 82.30% compared to random selection. Additionally, methods like Similarity-based Selection and Prediction Probability-based Selection have shown superior results on datasets like Cifar10 and Cifar100, outperforming traditional approaches. These advancements make it easier for you to train models even when data is scarce.
Reducing Annotation Costs and Time
The annotation process can be time-consuming and costly, especially for large datasets. Few-shot learning and active learning streamline this process by minimizing the amount of data you need to label. This efficiency translates into significant cost savings and faster project timelines.
Empirical data highlights these benefits. On the IMDB dataset, GPT-only annotations increased F1 scores from 0.8201 at 10% labeled data to 0.9629 at 50%, with costs ranging from 0.4603 to 2.3015. Hybrid models achieved similar accuracies to human-only labels but at a fraction of the cost. These results demonstrate how these techniques optimize the annotation process while maintaining high model performance.
Enhancing Real-World Model Performance
Few-shot learning and active learning not only save resources but also improve model performance in real-world scenarios. By focusing on the most challenging or diverse data points, these methods help computer vision models generalize better to unseen data.
Quantifiable improvements further illustrate this point. For instance, few-shot learning achieved 1-shot accuracy of 66.57% and 5-shot accuracy of 84.42% on the MiniImageNet dataset. On the FC100 dataset, it reached 44.78% and 66.27% for 1-shot and 5-shot tasks, respectively. These results highlight how these techniques enhance evaluation on unseen data, making your models more robust and reliable for computer vision tasks.
By leveraging few-shot learning and active learning, you can build a machine vision system that excels in efficiency, accuracy, and adaptability. These methods empower you to overcome data limitations and create models that perform exceptionally well in diverse applications.
Applications of Few-Shot and Active Learning in Machine Vision

Image Classification
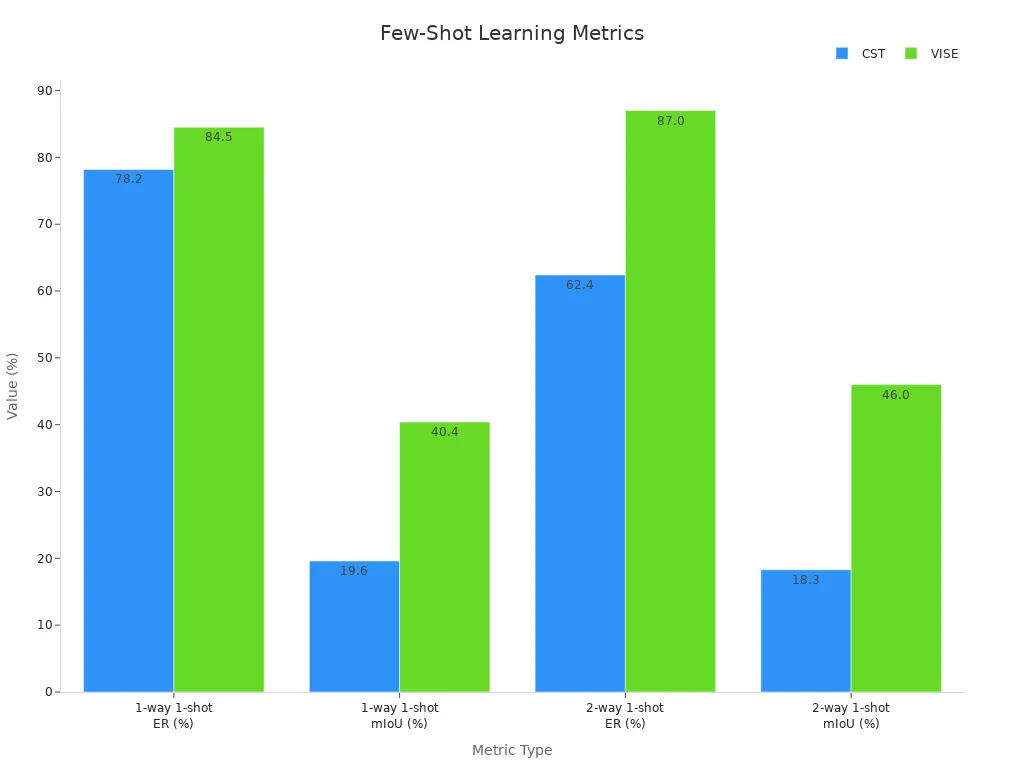
Few-shot learning and active learning have revolutionized image classification by enabling models to perform well with minimal labeled data. These techniques allow you to train models that generalize effectively, even when data is scarce. For instance, few-shot learning methods like DINO, CST, and VISE have demonstrated impressive results in classification tasks. The table below highlights their performance:
| Method | 1-way 1-shot ER (%) | 1-way 1-shot mIoU (%) | 2-way 1-shot ER (%) | 2-way 1-shot mIoU (%) |
|---|---|---|---|---|
| DINO | - | 12.1 | - | 7.4 |
| CST | 78.2 | 19.6 | 62.4 | 18.3 |
| VISE | 84.5 | 40.4 | 87.0 | 46.0 |
These results show that VISE outperforms other methods in both classification accuracy and segmentation tasks. By leveraging these techniques, you can achieve robust performance in image classification, even with limited data.
Object Detection
Few-shot object detection has transformed how you approach tasks requiring precise identification of objects within images. Active learning enhances this process by optimizing the selection of relevant bounding boxes for annotation. This ensures that the most informative samples are prioritized, reducing the need for extensive labeling. By combining these techniques, you can improve the accuracy of object detection systems while minimizing costs and time.
Medical Imaging
In medical imaging, few-shot learning addresses the challenge of data scarcity by enabling models to learn from a small number of labeled examples. A review of 80 articles published between 2018 and 2023 highlights the effectiveness of this approach. Few-shot learning has proven particularly useful in clinical tasks, where obtaining labeled data is often difficult. Statistical analysis of these studies shows that meta-learning methods significantly enhance model performance, making them invaluable for medical imaging applications.
By applying few-shot learning and active learning, you can build systems that excel in tasks like disease diagnosis and anomaly detection. These techniques not only improve accuracy but also reduce the time and cost associated with data annotation.
Autonomous Vehicles and Robotics
Few-shot and active learning techniques play a critical role in advancing autonomous vehicles and robotics. These systems rely on accurate perception and decision-making, which require vast amounts of labeled data. However, collecting and labeling such data for every possible scenario is impractical. You can overcome this challenge by using these innovative learning methods.
Few-shot learning enables autonomous systems to recognize new objects or scenarios with minimal labeled examples. For instance, a self-driving car might encounter a rare road sign or an unusual obstacle. With few-shot learning, the car can quickly adapt and make accurate decisions without needing extensive retraining. This adaptability ensures safer and more reliable navigation.
Active learning enhances this process by identifying the most informative data points for labeling. Imagine a robot navigating a warehouse. Instead of labeling every possible object, active learning helps prioritize the most uncertain or diverse samples. This targeted approach reduces annotation costs and accelerates the training process.
Tip: Combining few-shot and active learning allows you to build systems that learn efficiently while maintaining high performance in dynamic environments.
In robotics, these techniques improve tasks like object manipulation and path planning. A robot equipped with few-shot learning can grasp new objects after seeing just a few examples. Active learning ensures the robot focuses on learning from the most challenging tasks, improving its overall efficiency.
| Application | Few-Shot Learning Benefit | Active Learning Benefit |
|---|---|---|
| Self-Driving Cars | Recognizing rare road signs | Prioritizing uncertain scenarios |
| Warehouse Robots | Adapting to new objects | Reducing labeling efforts |
By leveraging these methods, you can create autonomous systems that adapt to new challenges with minimal data. These advancements bring us closer to a future where autonomous vehicles and robots operate seamlessly in complex, real-world environments.
Few-shot learning and active learning have reshaped how you approach machine vision challenges. Few-shot learning trains models with minimal labeled data, enabling them to generalize from just a few examples. Active learning selects the most valuable data points for labeling, improving efficiency and reducing costs. Together, these techniques create a powerful few-shot learning and active learning machine vision system that addresses data scarcity and enhances model performance.
The future of these methods looks promising. You can expect advancements that make machine vision systems even smarter and more adaptable. These techniques will continue to drive innovation in fields like medical imaging, robotics, and autonomous vehicles.
FAQ
1. How does few-shot learning differ from traditional machine learning?
Few-shot learning trains models using only a small number of labeled examples. Traditional machine learning requires large datasets to achieve similar performance. Few-shot learning focuses on generalizing quickly from limited data, making it ideal for tasks where labeled data is scarce or expensive to obtain.
2. Can active learning reduce labeling costs significantly?
Yes, active learning reduces labeling costs by selecting only the most informative data points for annotation. This targeted approach minimizes the amount of data you need to label while maintaining high model accuracy. It’s especially useful when labeling is time-consuming or expensive.
3. What are some real-world applications of these techniques?
Few-shot and active learning excel in fields like medical imaging, autonomous vehicles, and robotics. For example, they help classify rare diseases, detect objects in self-driving cars, and enable robots to adapt to new tasks with minimal training data.
4. Are these techniques suitable for small businesses?
Absolutely! Few-shot and active learning are cost-effective solutions for businesses with limited resources. They allow you to build efficient machine vision systems without requiring extensive labeled datasets, making them accessible even for small-scale projects.
5. How do I choose between few-shot and active learning?
You don’t have to choose one over the other. Few-shot learning works best when labeled data is scarce, while active learning optimizes the labeling process. Combining both techniques creates a powerful system that addresses data scarcity and improves model performance efficiently.
Tip: Start with few-shot learning for small datasets and integrate active learning to refine your model further.
See Also
The Impact of Deep Learning on Machine Vision Technology
Essential Insights on Transfer Learning for Machine Vision
Utilizing Synthetic Data to Improve Machine Vision Systems
Important Image Processing Libraries for Machine Vision Applications