Exploring the Basics of Long Short-Term Memory LSTM

If you've ever wondered how machines understand sequences like text or sound, you're in for a treat with the Long Short-Term Memory LSTM machine vision system. This type of recurrent neural network is built to handle sequential data while keeping track of long-term dependencies. Unlike traditional RNNs, LSTMs don’t struggle with fading memory when processing long sequences. They solve the vanishing gradient problem, ensuring stable learning across time steps.
Here’s the kicker: the Long Short-Term Memory LSTM machine vision system outperforms vanilla RNNs by 5-10% in accuracy for language tasks and maintains robust gradients over longer sequences. Plus, their training speed isn’t much slower than GRUs, making them a smart choice for tackling complex patterns in data.
Key Takeaways
- LSTMs work with data sequences, making them useful for tasks like translating languages and recognizing speech.
- Unlike regular RNNs, LSTMs keep important information for a long time, solving the problem of losing details over time.
- LSTMs have three gates—forget, input, and output—that control information. They save useful details and remove unneeded ones.
- Bidirectional LSTMs read data forward and backward, helping them understand context better and handle harder tasks.
- LSTMs are flexible and used in many areas like money management, healthcare, and video study, giving accurate results and helpful insights.
Understanding Long Short-Term Memory
Purpose of LSTM in sequential data processing
When you think about tasks like predicting stock prices, translating languages, or recognizing speech, they all have one thing in common: they involve sequences. A sequence is just a series of data points that are connected, like words in a sentence or notes in a song. The long short-term memory (LSTM) model is designed specifically to handle these kinds of tasks. It excels at sequence learning by remembering important information over long periods, which is something traditional models often struggle with.
LSTMs are widely used in real-world applications. For example:
- They help in time series forecasting, like predicting weather patterns or stock market trends.
- They’re used in language modeling, which powers things like text generation and machine translation.
- They play a big role in speech recognition, making virtual assistants like Siri or Alexa understand you better.
What makes LSTMs so special? They can capture long-term dependencies in data. This means they don’t just focus on the most recent part of a sequence but also consider what happened earlier. For instance, when translating a sentence, the LSTM model doesn’t forget the subject of the sentence even after processing several words. This ability to maintain context is why LSTMs are so effective in sequence learning.
Here’s a quick look at how LSTMs shine in different areas:
| Application Area | Findings |
|---|---|
| Hydrological Predictions | LSTMs have advanced sequence processing in predicting water flow. |
| Speech Recognition | They’ve improved performance in recognizing spoken words. |
| Trajectory Prediction | LSTMs effectively predict movement paths, like in self-driving cars. |
| Correlation Analysis | They analyze relationships in sequential data with high efficiency. |
How LSTM addresses the limitations of traditional RNNs
Traditional recurrent neural networks (RNNs) were the first models designed to handle sequences. They seemed promising at first, but they had a major flaw: the vanishing gradient problem. This issue made it hard for RNNs to learn long-term dependencies. In simple terms, they would "forget" earlier parts of a sequence as they processed more data. Imagine trying to understand a story but forgetting the beginning by the time you reach the end. That’s what RNNs struggled with.
LSTMs solve this problem with their unique architecture. They use special components like gates and a cell state to control what information gets remembered or forgotten. Think of the cell state as a conveyor belt that carries important information through the sequence. The gates act like traffic signals, deciding whether to let new information in, keep old information, or remove unnecessary details. This clever design ensures that LSTMs can maintain long-term dependencies without losing focus.
Here’s how LSTMs compare to traditional RNNs in terms of performance:
| Metric | LSTM Performance | Traditional RNN Performance |
|---|---|---|
| Mean Absolute Error (MAE) | 175.9 | Higher (less accurate) |
| Root Mean Squared Error (RMSE) | 207.34 | Higher (less accurate) |
| Accuracy (%) | 96.41 | Lower |
By addressing the limitations of RNNs, LSTMs have become the go-to choice for sequence learning tasks. They’re not just accurate but also efficient during training. This makes them ideal for applications where both precision and speed matter, like real-time speech recognition or financial modeling.
LSTM Architecture and Components
Structure of an LSTM cell
At the heart of lstm networks lies the LSTM cell, a building block designed to process sequential data effectively. Think of it as a tiny decision-maker that decides what information to keep, update, or discard as it processes data step by step. This structure allows the model to maintain context over long sequences, which is crucial for tasks like language translation or stock price prediction.
The LSTM cell has a unique design that includes several components working together. It uses gates to control the flow of information and a memory cell to store important details. The memory cell acts like a conveyor belt, carrying information through the sequence without much change. This ensures that critical data isn't lost as the model processes each step.
Here’s a simplified explanation of how an LSTM cell works:
- It takes the current input and the previous hidden state as inputs.
- It uses gates to decide what information to keep, update, or forget.
- It updates the memory cell based on these decisions.
- It calculates the new hidden state, which is passed to the next step in the sequence.
This structure makes lstm architecture highly effective for tasks involving long-term dependencies.
Key components: Forget Gate, Input Gate, and Output Gate
The magic of LSTM networks lies in its three gates: the forget gate, input gate, and output gate. Each gate plays a specific role in managing the flow of information.
The LSTM network architecture consists of three parts: the Forget gate, the Input gate, and the Output gate, each controlling the flow of information in and out of the memory cell.
- Forget Gate: This gate decides what information to discard from the memory cell. It uses a sigmoid activation function to filter out unnecessary details. For example, if you're reading a book, the forget gate helps you ignore irrelevant details while focusing on the main plot.
- Input Gate: This gate determines what new information to add to the memory cell. It combines the current input and the previous hidden state to decide which details are worth remembering.
- Output Gate: This gate decides what information to pass to the next step in the sequence. It filters the updated memory cell through a sigmoid activation function and outputs the relevant details.
These gates work together to ensure that the LSTM cell retains important information while discarding irrelevant data.
Role of the cell state in maintaining memory
The cell state is the backbone of the LSTM architecture. It acts as a long-term memory storage, carrying information through the sequence without much modification. This allows the model to maintain context over long periods, which is essential for tasks like speech recognition or time series forecasting.
Here’s how the cell state works:
- The forget gate removes unnecessary information from the cell state.
- The input gate adds new, relevant information to it.
- The output gate filters the updated cell state to produce the new hidden state.
The cell state is processed through a tanh activation function to constrain its values between -1 and 1. This ensures that the memory cell doesn’t overflow with information. The final hidden state is calculated by combining the previous hidden state and the current input through a sigmoid activation. This creates a filter vector that is multiplied with the squished cell state, resulting in the updated hidden state.
To give you an idea of how effective this design is, here’s a table showcasing experimental results across different datasets:
| Dataset | Model | Accuracy Range | Convergence Rate | Performance Rank |
|---|---|---|---|---|
| NSL-KDD | SSA-LSTMIDS | 0.86 - 0.98 | Rapid | 1 |
| JAYA-LSTMIDS | 0.86 - 0.98 | Moderate | 2 | |
| PSO-LSTMIDS | 0.86 - 0.98 | Slow | 3 | |
| CICIDS 2017 | SSA-LSTMIDS | 0.86 - 0.98 | Rapid | 1 |
| JAYA-LSTMIDS | 0.86 - 0.98 | Moderate | 2 | |
| PSO-LSTMIDS | 0.86 - 0.98 | Slow | 3 | |
| Bot-IoT | SSA-LSTMIDS | Highest | Rapid | 1 |
| JAYA-LSTMIDS | Mid-range | Moderate | 2 | |
| PSO-LSTMIDS | Lowest | Slow | 3 |
This table highlights how LSTM networks consistently outperform other models in terms of accuracy and convergence rate. The combination of gates and the memory cell makes this possible, ensuring that the model can handle complex sequential data with ease.
LSTM vs. Traditional RNNs
Challenges with RNNs: The vanishing gradient problem
Have you ever tried to remember the beginning of a long story while reading its end? That’s exactly what traditional recurrent neural networks (RNNs) struggle with. They face something called the vanishing gradient problem. When an RNN processes a long sequence, the gradients (used to update the model during learning) shrink as they move backward through the network. This makes it nearly impossible for the model to learn long-term dependencies. In simpler terms, RNNs tend to "forget" earlier parts of the sequence, focusing only on the most recent data. This limitation makes them less effective for tasks like language translation or time series forecasting, where context from earlier steps is crucial.
How LSTM overcomes these challenges
This is where the long short-term memory (LSTM) model shines. It was specifically designed to tackle the vanishing gradient problem. LSTMs use a clever architecture with gates and a cell state to manage information flow. The forget gate decides what to discard, the input gate determines what new information to add, and the output gate controls what gets passed to the next step. These gates work together to ensure the network retains important details over long sequences. The cell state acts like a conveyor belt, carrying information forward without much change. This design allows LSTMs to maintain context and learn long-term dependencies effectively.
Advantages of LSTM in real-world applications
LSTMs have proven their worth in various industries. For example:
- In healthcare predictive modeling, researchers at Stanford University used LSTM networks to analyze patient histories and predict medical complications.
- In autonomous driving, companies like Tesla and Waymo rely on LSTMs to process sensor data and predict pedestrian movements, vehicle paths, and road hazards.
These applications highlight the versatility of LSTMs. They excel at learning from sequential data, making them ideal for tasks like speech recognition, financial modeling, and video analysis. Unlike traditional RNNs, LSTMs can handle complex patterns and noisy data, ensuring accurate predictions and robust performance.
Extensions of LSTM: Bidirectional LSTM
What is Bidirectional LSTM?
Imagine reading a sentence where you can only look at the words from left to right. You’d miss out on understanding how earlier and later words connect. That’s where Bidirectional LSTM (BLSTM) steps in. It’s an advanced version of the long short-term memory lstm machine vision system that processes data in two directions—forward and backward. This means it captures context from both the past and the future, making it incredibly powerful for tasks like speech recognition and text generation.
Unlike traditional LSTMs, which only move in one direction, BLSTM uses two separate LSTM layers. One processes the sequence from start to end, while the other goes in reverse. By combining the outputs of both layers, BLSTM provides a richer understanding of the data. This dual approach makes it ideal for applications where context matters, like translating languages or analyzing videos.
How BLSTM enhances context understanding
You might wonder, how does processing in two directions improve context? Think of it like watching a movie scene from two angles. BLSTM captures dependencies in both directions, ensuring no detail is missed. For example, in image captioning, it doesn’t just focus on the objects in the image but also considers their relationships to generate meaningful descriptions.
Here’s a quick look at how BLSTM improves context understanding:
| Key Findings | Description |
|---|---|
| Effective Handling of Sequential Data | Excels in processing sequences, crucial for tasks like image captioning. |
| Improved Image-Text Representation | Enhances how images are represented in textual form for better context. |
| Contextual Understanding of Sentences | Captures dependencies in both directions, improving sentence coherence. |
| Flexibility for Multi-Word Phrases | Generates complex, contextually relevant phrases with ease. |
Studies show that BLSTM performs exceptionally well on datasets like Flickr8k and MSCOCO, where it outshines other models in generating accurate captions. Its ability to process sequences bidirectionally ensures a deeper understanding of context, making it a game-changer in many fields.
Applications of BLSTM in machine vision systems and beyond
The long short-term memory lstm machine vision system becomes even more versatile with BLSTM. In machine vision, BLSTM helps analyze video frames by understanding both past and future movements. This is crucial for tasks like gesture recognition and autonomous driving. For instance, BLSTM can predict a pedestrian’s movement by analyzing their current position and where they’re likely to go next.
Here are some performance metrics that highlight BLSTM’s effectiveness in machine vision:
| Metric | Description |
|---|---|
| Accuracy | Measures how often the model makes correct predictions. |
| Precision | Evaluates the accuracy of positive predictions. |
| F1-Score | Balances precision and recall to provide a comprehensive performance metric. |
BLSTM has also proven its worth in traffic forecasting. It outperforms other models across multiple prediction horizons, even under high-demand scenarios. This makes it a reliable choice for applications requiring precise and timely predictions.
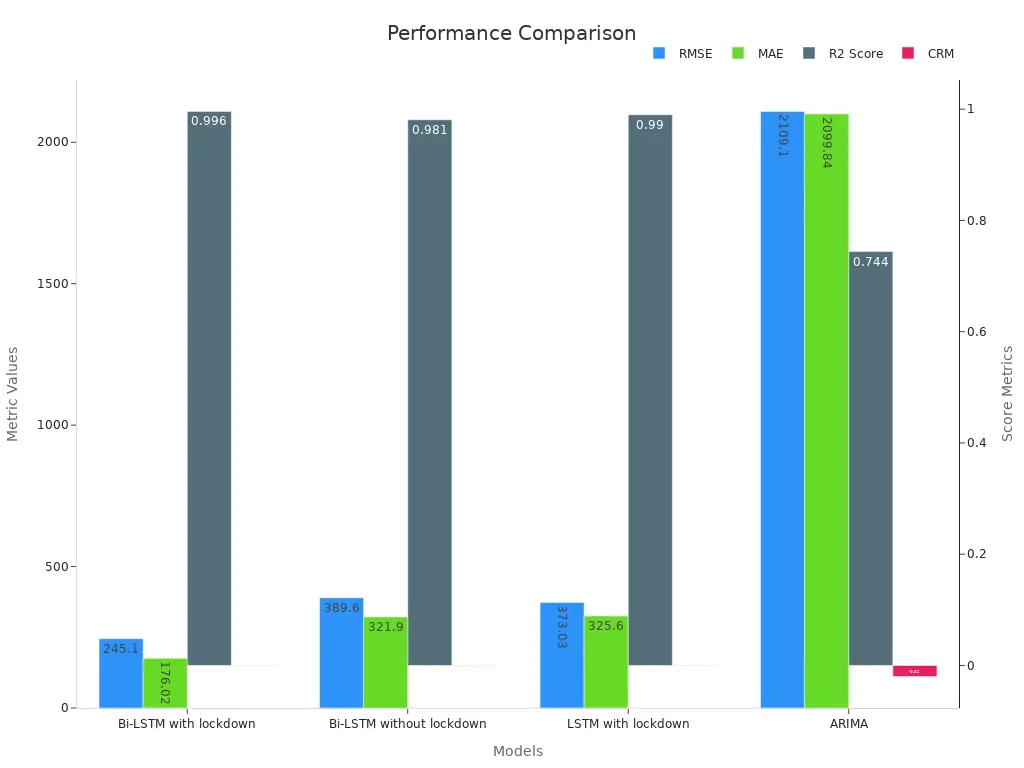
Whether it’s improving speech recognition, generating captions, or enhancing video analysis, BLSTM takes the capabilities of the long short-term memory lstm machine vision system to the next level. Its ability to process sequences in both directions ensures unmatched accuracy and context understanding.
Applications of Long Short-Term Memory
Natural language processing: Machine translation and text generation
Have you ever wondered how your favorite translation app understands entire sentences instead of just individual words? That’s where the LSTM model shines. It processes sequences of words, capturing relationships between distant elements to ensure accurate translations. For example, when translating a sentence from English to French, the network doesn’t just focus on the current word but also considers the context of earlier and later words. This ability to analyze the entire sequence makes LSTMs incredibly effective for machine translation.
Text generation is another area where LSTMs excel. They learn patterns in text data during training and use this knowledge to generate coherent and meaningful sentences. Whether it’s creating poetry, writing code, or even composing music lyrics, LSTMs can handle it all. Their architecture, designed to overcome the vanishing gradient problem, ensures they retain long-term dependencies, making them ideal for complex natural language processing tasks.
- LSTMs handle long sequences effectively, capturing relationships between distant elements.
- They improve accuracy in tasks like machine translation by analyzing the entire context.
- Their ability to learn complex patterns makes them suitable for various NLP applications.
Speech recognition and audio processing
When you talk to your virtual assistant, how does it understand your speech? LSTMs play a big role here. They process audio sequences, identifying patterns in your speech to convert it into text or commands. Their ability to retain context over long sequences makes them perfect for speech recognition tasks, where understanding the flow of words is crucial.
Here’s a quick look at how LSTMs perform in speech recognition compared to other models:
| Model | STOI Improvement | PESQ Improvement | WER (%) |
|---|---|---|---|
| LSTM-AttenSkips-IRM | +4.4% | +0.20 (9.09%) | 19.13 |
| LSTM-AttenSkips-IBM | +6.7% | +0.31 (14.09%) | N/A |
| LSTM-AttenSkips-IRM vs DNN | +5.10% | N/A | N/A |
| LSTM-AttenSkips-IRM vs CNN | +9.7% | N/A | N/A |
| LSTM-AttenSkips-IBM vs CNN | +4.90% | N/A | N/A |
| LSTM-AttenSkips-IBM vs GAN | +9.50% | N/A | N/A |
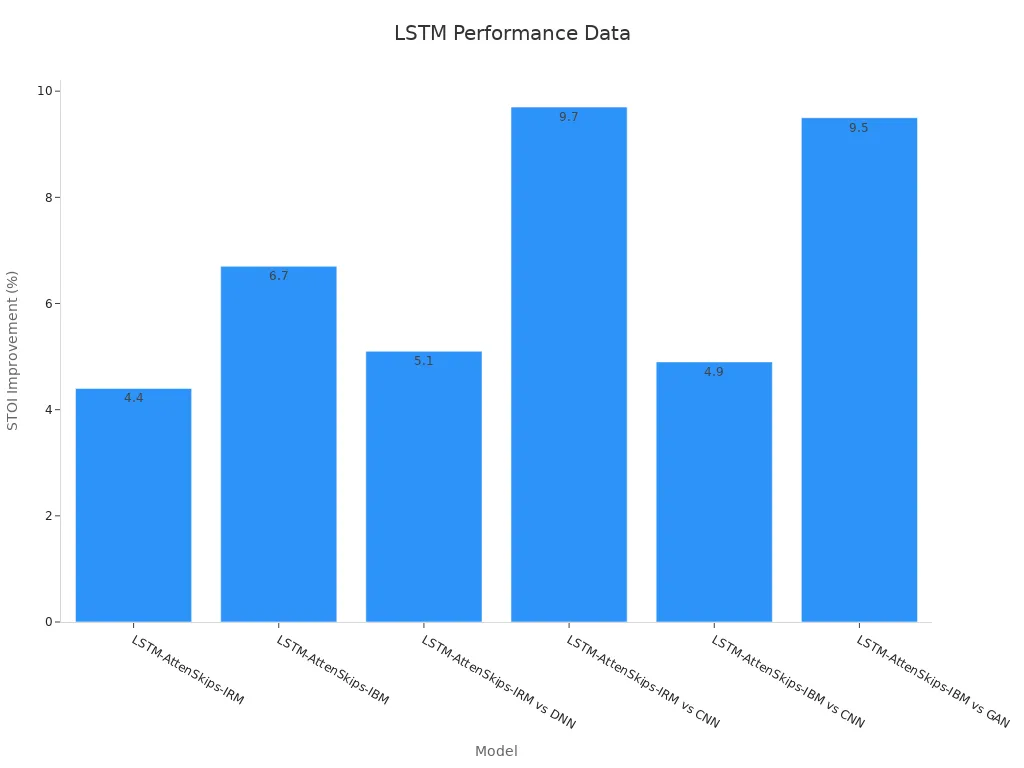
These results highlight how LSTMs outperform other models in improving speech clarity and reducing word error rates. Their ability to handle noisy data makes them a reliable choice for audio processing tasks.
Time series forecasting and financial modeling
Time series forecasting is all about making predictions based on past data. Whether it’s forecasting stock prices, weather patterns, or energy consumption, LSTMs are up to the task. They analyze sequences of data points, identifying trends and patterns to make accurate predictions. For example, in financial modeling, LSTMs can predict stock market movements by analyzing historical price data and market trends.
Their ability to retain long-term dependencies gives them an edge over traditional models. Unlike simpler methods, LSTMs don’t just focus on recent data. They consider the entire sequence, ensuring more accurate and reliable forecasts. This makes them a popular choice in industries where precise predictions are critical.
Tip: If you’re working with time series data, consider using LSTMs for their ability to handle complex patterns and noisy datasets.
Video analysis and gesture recognition
When you watch a video, your brain automatically picks up on movements, gestures, and patterns. Machines, however, need a little help to do the same. That’s where LSTMs step in. They’re great at analyzing sequences, making them perfect for video analysis and gesture recognition tasks. Whether it’s identifying hand gestures for gaming or tracking movements in surveillance footage, LSTMs can handle it all.
Here’s how it works. LSTMs process video frames as sequential data, capturing the relationships between movements over time. This ability to understand long-term dependencies makes them ideal for recognizing gestures or predicting actions. For example, in sports analytics, LSTMs can track a player’s movements to predict their next move. In healthcare, they’re used to monitor patient gestures for rehabilitation exercises.
What makes LSTMs so effective? Their architecture allows them to focus on relevant parts of the input sequence. Enhancements like attention mechanisms and squeeze-and-excitation blocks take this even further. These features help the model zero in on important details, ensuring accurate recognition even in complex scenarios. By directly accessing past outputs and weighting inputs, LSTMs can manage intricate patterns and dependencies over time.
Let’s look at some benchmarks that highlight LSTM’s robustness in handling noisy sequential data:
| Architecture | Model | Robustness Score |
|---|---|---|
| Recurrent | LSTM | 0.6411 ± 0.3412 |
| Recurrent | GRU | 0.5948 ± 0.3543 |
These scores show how LSTMs outperform other models, even when the data isn’t perfect. Their ability to handle disturbances makes them reliable for real-world applications.
LSTMs also shine across multiple domains. Here’s a snapshot of their versatility:
| Metric | Description |
|---|---|
| Robustness to data sparsity | Performs well even with 50% data retention, showing resilience. |
| Model performance across domains | Consistently outperforms standalone models across engineering datasets. |
| Scalability analysis | Training time increases linearly with dataset size, proving computational efficiency. |
| Performance with noisy data | Maintains accuracy with up to 10% noise, demonstrating reliability. |
| Hyperparameter sensitivity | Delivers stable results across varied hyperparameters. |
From gesture-based gaming to video surveillance, LSTMs are transforming how machines understand motion. Their ability to capture long-term dependencies and handle noisy data makes them a go-to choice for video analysis and gesture recognition tasks.
Benefits of Using LSTM
Capturing long-term dependencies in data
When working with sequential data, you often need to remember information from earlier steps to make sense of the current one. That’s where LSTMs shine. They’re specifically designed to capture long-term dependencies, ensuring that important details from the past aren’t forgotten. For example, when translating a sentence, an LSTM can remember the subject introduced at the beginning, even after processing several words. This ability makes them ideal for tasks like language translation, speech recognition, and time series forecasting.
The secret lies in their architecture. LSTMs use gates—forget, input, and output—to manage information flow. Each gate has a specific role:
- The forget gate removes irrelevant details to keep the memory clean.
- The input gate decides what new information to add.
- The output gate determines what to share with the next step.
Here’s a quick summary of how these gates work:
| Gate Type | Function | Purpose in LSTM |
|---|---|---|
| Forget Gate | Discards irrelevant information to prevent overload | Maintains focus on relevant data |
| Input Gate | Determines valuable new information to add to memory | Updates internal memory with new data |
| Output Gate | Decides what part of memory to output based on current input | Controls the information flow to output |
This design ensures that LSTMs excel at learning patterns in sequential data without losing track of earlier context.
Robustness in handling noisy sequential data
Sequential data often comes with noise—irrelevant or inconsistent information that can confuse models. LSTMs handle this challenge like pros. Their advanced architecture filters out the noise while focusing on meaningful patterns. This makes them reliable for tasks like speech recognition, where background sounds can interfere, or financial modeling, where market fluctuations add unpredictability.
By addressing issues like vanishing gradients, LSTMs maintain stable learning even with noisy inputs. Their ability to adapt to disturbances ensures accurate predictions, making them a trusted choice across industries.
Versatility across domains and tasks
LSTMs aren’t just powerful—they’re versatile. You’ll find them in a wide range of applications, from natural language processing to video analysis. Their ability to capture long-term dependencies and handle complex patterns makes them suitable for diverse tasks. Whether it’s predicting stock prices, generating text, or recognizing gestures, LSTMs deliver impressive results.
Here’s why they stand out:
- They’re built to handle deep learning challenges, like managing long sequences.
- Their architecture solves problems traditional RNNs struggle with, like gradient issues.
- They’ve shown significant improvements in accuracy across tasks like machine translation and data mining.
In short, LSTMs are your go-to tool for tackling sequential data problems, no matter the domain.
Long Short-Term Memory (LSTM) networks have revolutionized how you handle sequential data. They solve problems like vanishing gradients, making them ideal for tasks that require understanding long-term dependencies. With components like the forget gate, input gate, and output gate, LSTMs manage information flow efficiently, outperforming traditional RNNs in accuracy and reliability.
If you're curious about how LSTMs can improve your projects, dive deeper into their architecture and explore advanced concepts like Bidirectional LSTM. The more you learn, the better you'll understand how these models simplify complex patterns and enhance training outcomes.
FAQ
What makes LSTM better than traditional RNNs for sequence prediction?
LSTM excels because it remembers long-term dependencies. Its unique gates manage what to keep, update, or forget, solving the vanishing gradient problem. This makes it perfect for sequence prediction tasks like language translation or anomaly detection.
Can LSTM handle noisy data during training and inference?
Yes, LSTM is robust with noisy data. Its architecture filters out irrelevant information while focusing on meaningful patterns. This makes it reliable for tasks like speech synthesis and anomaly detection, even when the input data isn’t perfect.
How does LSTM improve anomaly detection?
LSTM learns patterns in sequential data, making it great for spotting anomalies. It predicts what should happen next in a sequence. If the actual data deviates significantly, it flags it as an anomaly. This is useful in fraud detection and system monitoring.
Is LSTM suitable for real-time applications?
Absolutely! LSTM performs well in real-time tasks like speech recognition and video analysis. Its ability to process sequences efficiently during training and inference ensures quick and accurate results, even in time-sensitive scenarios.
Can LSTM be used for language synthesis?
Yes, LSTM is widely used for language synthesis. It generates coherent text by learning patterns in language data. Whether it’s creating poetry, writing stories, or generating dialogue, LSTM handles the task with impressive accuracy.
See Also
Grasping The Fundamentals Of Deep Learning Techniques
An Introduction To The Essentials Of Machine Vision Sorting
Key Insights On Transfer Learning For Machine Vision
Understanding Few-Shot And Active Learning Methods In Vision