Exploring the Concept of Occlusion in Vision Systems

Occlusion occurs when one object partially or fully blocks another in a scene, making it difficult for an occlusion machine vision system to detect or track objects accurately. This phenomenon is common in real-world scenarios, such as crowded streets or cluttered environments. For you, as a user or developer, addressing occlusion is critical to improving the reliability of vision systems.
Occlusion challenges can significantly impact object detection and tracking within an occlusion machine vision system. Classical methods often fail when objects overlap, leading to identity loss or tracking errors. Small objects are especially vulnerable, as they can easily blend into the background or other objects. Advanced techniques, like multi-frame receptive networks, are now being used to enhance tracking accuracy and robustness in these systems.
Key Takeaways
- Occlusion happens when one thing blocks another, making it hard for vision systems to see or follow objects correctly.
- Smart tools like neural networks and depth sensing help vision systems handle occlusions better.
- Adding extra data and using fake datasets improve training, helping systems find objects in tricky occlusion situations.
- Looking at objects from different views and times makes it easier to spot blocked objects.
- Fixing occlusions is important for self-driving cars, virtual reality, and medical pictures to stay safe and work well.
Understanding Occlusion in Machine Vision Systems
What is occlusion, and how does it occur?
Occlusion happens when one object blocks another in a scene, either partially or completely. In computer vision, this phenomenon disrupts the ability of systems to identify or track objects accurately. You encounter occlusion frequently in real-world scenarios, such as crowded streets, sports events, or industrial environments. For example, in sports analytics, players often overlap, making it challenging for an object detection model to differentiate between individuals.
Occlusion occurs due to various factors, including the position of objects relative to the camera, lighting conditions, and the complexity of the scene. Partial occlusions arise when only a portion of an object is hidden, while complete occlusions occur when the object is entirely obscured. These situations demand robust algorithms to ensure reliable detection and tracking.
Occlusions consistently pose challenges for computer vision systems, including medical imaging, autonomous vehicles, and object recognition. Studies show that even minor occlusions, such as blocking a few pixels, can disrupt predictions. Deep learning models often rely on specific visual cues, like the ear of a dog, to classify objects. When these cues are occluded, the system's robustness declines significantly.
Types of occlusion: partial vs. full occlusion
Partial occlusions occur when only a segment of an object is hidden from view. For instance, a car partially blocked by a tree still reveals enough features for detection. These occlusions often lead to errors in segmentation or classification, as the system struggles to interpret incomplete data.
Complete occlusions, on the other hand, occur when an object is entirely obscured. In such cases, the occlusion machine vision system loses all visual information about the object, making detection nearly impossible. Studies comparing partial and complete occlusions reveal that performance drops significantly under complete occlusion conditions.
Research shows that visual occlusion impacts spatial coordination and movement times. Adults perform better when objects are fully visible compared to partial occlusion scenarios. This highlights the importance of designing systems that can handle both types effectively.
Detecting occlusions and their impact on performance
Detecting occlusions is a critical step in ensuring the reliability of computer vision systems. Techniques like saliency maps and visual explainability tools help identify occluded regions in images. These methods allow you to pinpoint areas where the system struggles, enabling targeted improvements.
Experimental data from sports analytics demonstrates the effectiveness of advanced methods in detecting occlusions. These methods reduce false positives and recover occluded objects, improving precision and recall. For example:
| Method | Evaluation Value | Precision | Recall | F-measure |
|---|---|---|---|---|
| Method I | Lowest | N/A | N/A | N/A |
| Method II | Higher Recall | Lower | Higher | Higher |
| Method III | N/A | N/A | N/A | N/A |
Detecting occlusions also impacts performance metrics like classification accuracy and segmentation quality. As occlusion increases, accuracy drops, but techniques like inpainting recovery can mitigate these effects.
- Object detection models improve precision by 12.5% in occlusion cases.
- Recall increases by up to 15.8% due to interpolation mechanisms.
- F1 scores rise by an average of 14.1%, showcasing overall efficiency.
By addressing occlusions effectively, you can enhance the reliability of computer vision systems across diverse applications.
Occlusion Techniques in Vision Systems
Machine learning and neural networks for occlusion handling
Machine learning and neural networks play a vital role in managing occlusions in computer vision. These systems analyze pixel-level interactions to predict the characteristics of hidden objects. By leveraging advanced neural network architectures, you can improve the accuracy of object detection even when parts of the scene are obscured. For instance, convolutional neural networks (CNNs) excel at recognizing patterns in occluded images, while Vision Transformer (ViT) models demonstrate even greater accuracy under challenging conditions.
Recent studies reveal that CNN-based models outperform earlier approaches in handling partial occlusions. ViT models, however, achieve recognition accuracy levels closer to human performance. This makes them a preferred choice for applications requiring high precision. Certain types of occlusion, such as diffuse occlusion, still pose challenges, but neural networks continue to evolve to address these limitations.
| Model | AUC | Classification Accuracy | F1 Score | Precision | Recall | Specificity |
|---|---|---|---|---|---|---|
| Random Forest | 0.971 | 0.9 | 0.892 | 0.91 | 0.9 | 0.912 |
| Naive Bayes | 0.844 | 0.633 | N/A | N/A | N/A | N/A |
| Neural Network | 0.92 | 0.75 | N/A | N/A | N/A | N/A |
Additionally, techniques like SMT-based approaches verify the robustness of deep neural networks against occlusions. These methods efficiently identify weaknesses in models, ensuring they perform reliably in real-world scenarios.
Depth sensing and 3D reconstruction methods
Depth sensing and 3D reconstruction methods offer powerful solutions for handling occlusions. These techniques use depth information to create a more complete understanding of a scene, even when objects are partially or fully hidden. By integrating data from multiple sensors, you can overcome line-of-sight issues and achieve more accurate reconstructions.
A multi-sensor approach provides better coverage and smoother surfaces compared to single-sensor methods. While single-sensor systems often fail to capture occluded areas, techniques like TSDF fusion improve coverage. However, they may introduce noise in inconsistent regions. Combining multiple sensors compensates for these shortcomings, resulting in more reliable occlusion handling.
For example, in autonomous vehicles, depth sensing enables the detection of obstacles hidden behind other objects. This ensures safer navigation in complex environments. Similarly, in augmented reality applications, 3D reconstruction enhances the realism of virtual objects by accurately accounting for occlusions in the real world.
Data augmentation and synthetic datasets
Data augmentation is a key strategy for improving the performance of computer vision models under occlusion. By creating diverse training samples, you can help models learn to recognize objects in various conditions. Techniques like random erasing simulate occlusions by removing parts of an image, while rotation and flipping address viewpoint variations. These methods enhance the robustness of models, making them more effective in real-world scenarios.
Studies using datasets like MNIST and ImageNet show that data augmentation significantly improves model accuracy. Synthetic datasets also play a crucial role in training occlusion models. By generating artificial images, you can provide additional training data without the need for extensive real-world collection. Research indicates that synthetic images maintain comparable performance to real ones, with improvements in segmentation accuracy observed across multiple resolutions.
For example:
- Dice Score increases of 10.21%, 4.46%, and 6.51% were achieved at different resolutions.
- Supplementing with synthetic data led to further improvements, with p-values of 0.042, 0.030, and 0.033.
By incorporating data augmentation techniques and synthetic datasets, you can enhance the ability of computer vision systems to handle occlusions effectively. These methods not only improve accuracy but also reduce the time and cost associated with data collection.
Multi-view and temporal analysis techniques
Multi-view and temporal analysis techniques offer powerful solutions for handling occlusions in vision systems. These methods rely on combining data from multiple viewpoints or analyzing sequences of images over time. By doing so, you can reconstruct occluded objects and improve the accuracy of object detection and tracking.
Multi-view Analysis
Multi-view analysis involves capturing a scene from different camera perspectives. This approach allows you to gather complementary information about objects that may be hidden in one view but visible in another. For example, in a surveillance system, multiple cameras positioned around a room can collectively monitor areas that a single camera might miss. This redundancy ensures that occluded objects are still detectable.
One of the key benefits of multi-view analysis is improved matching accuracy. Techniques like Dynamic Time Warping (DTW) enhance the reliability of identifying objects or individuals across different camera angles. Additionally, majority voting methods aggregate data from multiple views to increase the overall performance of object matching. These strategies make multi-view analysis a robust tool for addressing occlusion challenges.
Temporal Analysis
Temporal analysis focuses on leveraging information from a sequence of images captured over time. By analyzing how objects move and change across frames, you can infer the presence of occluded objects. For instance, in autonomous vehicles, temporal analysis helps predict the trajectory of a pedestrian temporarily hidden behind a parked car. This predictive capability enhances safety and decision-making.
Temporal techniques also excel in efficiency. They often require less computational power, making them suitable for systems running on CPUs or small datasets. Moreover, these methods enable detailed analyses, allowing you to visualize and interpret data comprehensively.
Performance Benefits of Multi-view and Temporal Analysis
The combination of multi-view and temporal analysis techniques provides several measurable benefits. The table below summarizes these advantages:
| Performance Benefit | Description |
|---|---|
| Improved Matching Accuracy | Utilizes Dynamic Time Warping (DTW) for enhanced reliability in person identity matching. |
| Majority Voting | Increases matching performance across multiple camera perspectives. |
| Efficiency in Time and Cost | The method is efficient, particularly beneficial for small datasets and implemented on CPU. |
| Detailed Analyses | Allows for comprehensive data visualization and analysis. |
By integrating these techniques, you can create vision systems that are more resilient to occlusions. Whether you are working on surveillance, robotics, or augmented reality, these methods provide a reliable foundation for improving object detection and tracking.
Applications of Occlusion Handling
Autonomous vehicles and obstacle detection
Occlusion handling plays a vital role in ensuring the safety and efficiency of autonomous vehicles. These vehicles rely on computer vision to detect and track obstacles in real-time. However, occluded objects, such as a pedestrian hidden behind a parked car, can pose significant challenges. Advanced occlusion techniques, including depth sensing and temporal analysis, help predict the presence of these hidden obstacles.
Performance metrics illustrate the effectiveness of occlusion solutions in autonomous vehicles. For example, the table below highlights key metrics like collision prediction (CP) and time-to-collision (TTC), which measure the system's ability to detect and respond to occlusions promptly.
| Metric | CP (ms) | DCE (ms) | TTC (ms) | HR (ms) | BE (ms) |
|---|---|---|---|---|---|
| min | 0.0777 | 2.4519 | 0.0484 | 0.0911 | 0.0017 |
| median | 0.7939 | 4.3278 | 0.0803 | 0.1805 | 15.5444 |
| max | 1.8289 | 10.5934 | 0.1483 | 0.4063 | 40.7581 |
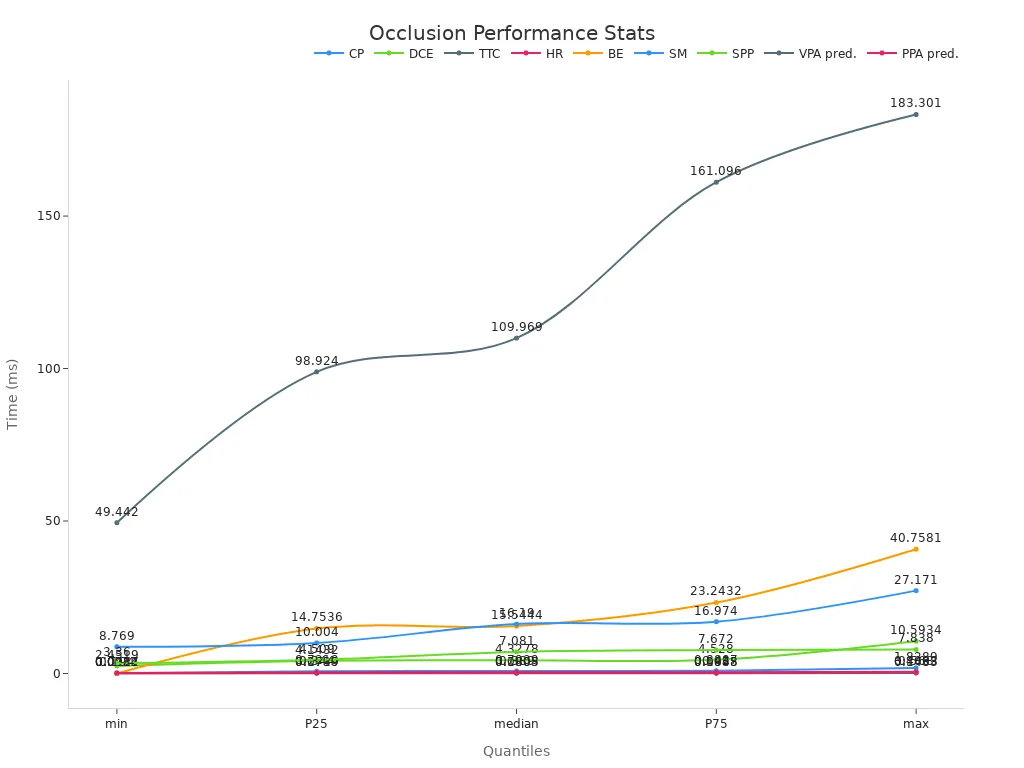
By addressing occlusions effectively, autonomous vehicles can navigate complex environments with greater accuracy and safety.
Augmented reality (AR) and virtual reality (VR)
In AR and VR systems, occlusion handling ensures a seamless integration of virtual and real-world elements. Without proper occlusion management, virtual objects may appear to float unrealistically or overlap incorrectly with real-world objects. This can disrupt the user experience and lead to spatial perception errors.
Researchers have developed methods that use real-world 3D models as occlusion masks to enhance AR applications. For instance:
- A case study in Stuttgart demonstrated how occlusion masks aligned with real buildings improved urban planning applications.
- Another study highlighted the importance of real-time occlusion handling to prevent user discomfort caused by virtual objects obscuring real ones.
These advancements make AR and VR systems more immersive and practical for applications like gaming, education, and urban design.
Medical imaging and diagnostics
Occlusion handling is critical in medical imaging, where accurate interpretation of occluded areas can impact diagnoses and treatment plans. Techniques like stereo matching and optical flow help extract meaningful information from images with occlusions. For example, in X-rays or MRIs, occluded objects such as overlapping tissues or bones can obscure critical details.
By managing occlusions effectively, medical imaging systems improve depth perception and motion analysis. This enhances the accuracy of diagnoses and supports better patient outcomes. Industries leveraging these techniques can achieve significant advancements in healthcare technology.
Occlusion handling addresses challenges in image processing tasks across industries. It improves depth perception, motion analysis, and object recognition, enhancing the performance of systems reliant on visual data.
Robotics and industrial automation
Robotics and industrial automation rely heavily on occlusion handling to improve efficiency and precision. When robotic systems encounter occlusions, such as blocked sensors or overlapping objects, their ability to perform tasks accurately can decline. By addressing these challenges, you can enhance the reliability of automated systems in manufacturing, logistics, and other industries.
Occlusion handling allows robotic arms to manipulate objects with greater precision. For example, when tubing or wires overlap, robots equipped with occlusion detection algorithms can adjust their movements to avoid errors. This capability ensures consistent performance, even in complex environments. Real-time sensors play a key role in detecting occlusions quickly, enabling robots to respond faster than manual methods.
Automation also improves testing processes. Robots can perform round-the-clock testing, increasing test coverage and accelerating testing cycles. Closed-loop systems autonomously resolve occlusions by adjusting flow and pressure, reducing downtime and improving success rates. These advancements make industrial automation more efficient and cost-effective.
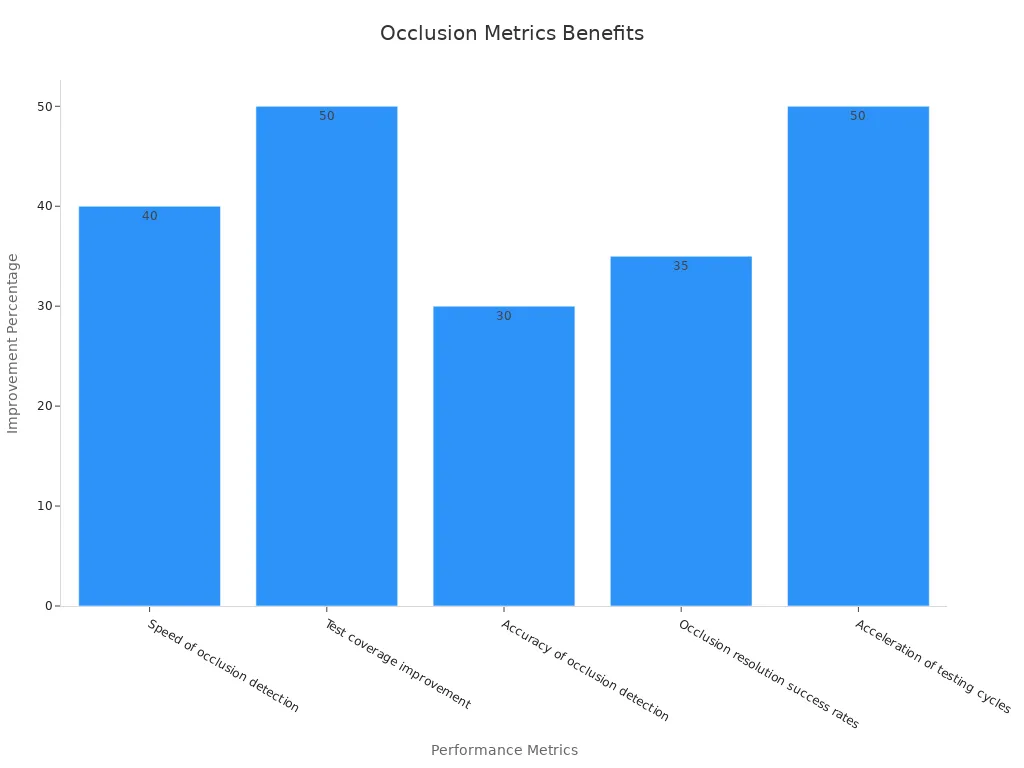
The table below highlights key performance metrics that demonstrate the benefits of occlusion handling in robotics and automation:
| Metric Description | Improvement Percentage | Notes |
|---|---|---|
| Speed of occlusion detection | 40% | Real-time sensors detect occlusions faster than manual methods. |
| Test coverage improvement | 50% | Round-the-clock testing enabled by automation. |
| Accuracy of occlusion detection | 30% | Robotic arms apply precise pressure and manipulate tubing consistently. |
| Occlusion resolution success rates | 35% | Closed-loop systems autonomously adjust flow and pressure to resolve occlusions. |
| Acceleration of testing cycles | 50% | Automation allows for continuous testing across multiple devices. |
By integrating occlusion handling techniques, you can optimize robotic systems for tasks requiring high precision and reliability. These advancements pave the way for smarter factories and more efficient industrial processes.
Technical Insights into Detecting Occlusions
Pixel-level analysis and segmentation techniques
Pixel-level analysis forms the foundation of detecting occluded regions in computer vision systems. By examining individual pixels, you can identify subtle changes in texture, color, or intensity that signal occlusions. Segmentation techniques, such as supervised learning models, play a critical role in this process. For example, the YOLOv11 model excels in occlusion segmentation within indoor environments like pig farming. It uses pixel-level labeling, multi-scale feature extraction, and a Path Aggregation Network to generate precise masks. A composite loss function, combining CIoU and Binary Cross-Entropy losses, ensures accurate detection even in challenging scenarios.
| Component | Description |
|---|---|
| Model | YOLOv11 |
| Purpose | Occlusion segmentation in the PigFRIS system |
| Methodology | Supervised segmentation using pixel-level labeling by human annotators |
| Key Features | Multi-scale feature extraction, Path Aggregation Network for feature fusion, pixel-wise mask generation |
| Loss Function | Composite loss function including CIoU loss and Binary Cross-Entropy loss |
| Application | Accurate detection of occlusions in indoor pig farming environments |
When evaluating occlusion handling, the severity of occlusions significantly impacts performance. Models trained on large datasets demonstrate greater robustness, especially against static occlusions. Transformers outperform CNNs in these tasks, highlighting the importance of selecting the right architecture for pixel-level analysis.
Performance optimization for real-time systems
Optimizing performance for real-time occlusion detection involves balancing speed and accuracy. Advanced algorithms now match predicted bounding boxes with detected ones, even when targets remain occluded for extended periods. For instance, a network feature extraction module has shown strong generalization capabilities, maintaining high robustness across various conditions. On the MOT dataset, optimization strategies achieved excellent results, particularly under high-resolution scenarios with high object detection confidence.
| Metric/Result | Description |
|---|---|
| Model Robustness | High robustness and strong generalization ability demonstrated. |
| Occlusion Handling | Successfully matched bounding boxes for targets occluded over 200 frames. |
| Performance Metrics | Outstanding results on MOT dataset under high-resolution conditions. |
By focusing on efficient algorithms and leveraging high-quality datasets, you can ensure real-time systems perform reliably, even in complex environments.
Balancing accuracy and computational efficiency
Balancing accuracy with computational efficiency remains a key challenge in evaluating occlusion handling. High-accuracy models often require significant computational resources, which can limit their usability in real-time applications. To address this, you can adopt lightweight architectures or optimize existing models. Techniques like pruning and quantization reduce model size without compromising performance. Pre-training on large datasets also enhances robustness, enabling models to handle occluded regions effectively while maintaining efficiency.
For example, models trained on diverse datasets perform better on dynamic occlusions, where objects move unpredictably. By prioritizing both accuracy and efficiency, you can create systems that excel in real-world scenarios without overwhelming computational resources.
Challenges and Future Developments in Occlusion Handling
Limitations of current occlusion techniques
Current occlusion techniques face several limitations that hinder their effectiveness in complex scenarios. Vision-based inspection systems struggle when objects have intricate shapes or internal components. These challenges arise because occlusions obscure critical features, reducing the camera's ability to capture accurate details. For example, inspecting machinery with overlapping parts often requires multiple cameras or advanced 3D imaging methods to reconstruct hidden geometries. While these solutions improve visibility, they increase system complexity and cost.
Another limitation lies in the reliance on static models that fail to adapt to dynamic environments. Many systems perform well under controlled conditions but falter in real-world applications where lighting, movement, and object variability introduce unpredictability. Addressing these limitations requires exploring effective ways to handle occlusions, such as integrating adaptive algorithms and multi-sensor setups.
Emerging technologies and research directions
Emerging technologies offer promising solutions to overcome occlusion challenges. Generative Adversarial Networks (GANs) are revolutionizing facial recognition by reconstructing missing features obscured by occlusions. These networks enhance image quality, bridging the gap between ideal and real-world conditions. For instance, GANs can restore facial details hidden by masks or shadows, improving recognition accuracy significantly.
Innovative segmentation techniques are also advancing occlusion handling. Lightweight semantic segmentation networks combine transformers and CNNs to achieve high accuracy with reduced computational demands. These methods are particularly effective in real-time applications, where efficiency is critical. Hardware advancements, such as modern GPUs optimized for deep learning, further enhance runtime performance. Additionally, integrating segmentation systems with edge computing and IoT technologies transforms visual data processing, enabling faster and more efficient operations.
The role of AI in advancing occlusion solutions
Artificial intelligence plays a pivotal role in advancing occlusion handling techniques. AI-powered systems demonstrate higher sensitivity and accuracy in detecting occlusions compared to traditional methods. For example, studies show that AI improves stroke detection in medical imaging, reducing critical time metrics like door-to-triage and CT-to-puncture times. These advancements highlight AI's ability to optimize processes and deliver reliable results in time-sensitive applications.
AI also excels in predictive modeling, enabling systems to anticipate occlusions before they occur. By analyzing longitudinal data, AI algorithms identify patterns and trends that inform better decision-making. For instance, demographic factors influencing occlusion performance can be integrated into predictive models, ensuring systems adapt to diverse conditions. As AI continues to evolve, its integration into machine vision systems will unlock new possibilities for handling occlusions effectively.
Addressing occlusion is crucial for improving the reliability of vision systems. Occlusion often disrupts visual understanding in 2D images, making tasks like face recognition and scene analysis challenging. By understanding the type, size, and location of occlusions, you can enhance recognition rates and reduce errors caused by misleading information. Techniques such as neural networks, depth sensing, and data augmentation have proven effective in managing occlusions across applications like autonomous vehicles, AR/VR, and medical imaging. Future advancements in AI and adaptive algorithms hold the potential to overcome current limitations, ensuring that your occlusion machine vision system performs robustly in dynamic environments.
FAQ
What is occlusion in computer vision?
Occlusion happens when one object blocks another in a scene, making it harder for vision systems to detect or track objects. This can occur in crowded environments or when objects overlap.
How do vision systems detect occlusions?
Vision systems use techniques like depth sensing, segmentation, and neural networks to identify occluded areas. These methods analyze pixel-level data or reconstruct scenes to locate hidden objects.
Why is occlusion handling important in autonomous vehicles?
Occlusion handling ensures vehicles detect obstacles hidden behind other objects. This improves navigation accuracy and safety, especially in complex environments like busy streets.
Can synthetic datasets help with occlusion challenges?
Yes, synthetic datasets simulate occlusion scenarios during training. They improve model robustness by exposing systems to diverse conditions, reducing errors in real-world applications.
What future advancements could improve occlusion handling?
Emerging technologies like AI-powered predictive modeling and lightweight segmentation networks promise better accuracy and efficiency. These advancements will help systems adapt to dynamic environments and handle occlusions more effectively.
See Also
An Overview of Computer Vision Models and Systems
Exploring Thresholding Techniques in Vision Systems
A Guide to Vision Processing Units in Vision Systems
The Role of Cameras in Machine Vision Systems
Grasping Object Detection Techniques in Modern Vision Systems