The Basics of Q-Learning in Machine Vision

Q-learning, a type of machine learning, helps systems learn by interacting with their environment. It uses a reward-based approach to improve decision-making over time. In machine vision, this technique enables systems to interpret visual data and make intelligent decisions. For example, in the two-armed bandit problem, participants adapted their choices based on changing reward probabilities. This adaptation mirrors how Q-learning refines strategies in tasks like object recognition and path planning. A Q-learning machine vision system can dynamically adjust to visual changes, making it crucial for applications like robotics and surveillance.
Key Takeaways
- Q-learning helps machines learn by using rewards from their surroundings. This method makes decisions better as time goes on.
- The Q-function predicts rewards for actions, helping machines choose wisely in different situations.
- A Q-table saves learned information, so machines can recall past actions and make faster, smarter decisions.
- It's important to balance trying new actions and using old strategies in Q-learning. Machines need to explore while also using what they know to get the best rewards.
- Q-learning improves things like tracking objects and planning paths in robots, making them work better and more dependably.
Understanding Q-Learning
Fundamentals of reinforcement learning
Reinforcement learning is a method where systems learn by interacting with their environment. You can think of it as trial-and-error learning. The system, called an agent, takes actions in different situations, called states. After each action, the agent receives feedback in the form of rewards. Positive rewards encourage the agent to repeat actions, while negative rewards discourage them. Over time, the agent learns to make better decisions to maximize rewards.
For example, imagine teaching a robot to navigate a maze. At first, the robot might bump into walls or take wrong turns. However, as it receives rewards for moving closer to the exit, it learns to avoid obstacles and find the shortest path. This process reflects the core principles of reinforcement learning.
To measure how well the agent learns, researchers often track trends like efficiency, success rate, and path optimization. Here's a summary:
| Evidence Type | Description |
|---|---|
| Efficiency Measure | Fewer steps per episode indicate more efficient behavior as the agent learns to reach goals quickly. |
| Downward Trend | A downward trend in steps per episode shows the agent discovering shorter paths as it learns. |
| Success Rate | The success rate reflects the agent's performance, starting low and increasing as it learns effective strategies. |
These trends highlight how reinforcement learning helps agents improve their behavior over time.
The Q-function and its role in decision-making
The Q-function is the heart of q-learning. It helps the agent decide which action to take in a given state. You can think of the Q-function as a mathematical formula that calculates the value of each action. This value, called the q-value, represents the expected reward for taking that action.
For instance, if the agent is in a state where it can either move forward or turn left, the Q-function calculates the q-values for both actions. The agent chooses the action with the highest q-value. Over time, as the agent learns from rewards, the Q-function becomes more accurate. This allows the agent to make smarter decisions.
How the Q-table stores state-action values
The Q-table is where the agent stores all its learned q-values. You can think of it as a lookup table. Each row represents a state, and each column represents an action. The values in the table show the expected rewards for each state-action pair.
When the agent encounters a state, it checks the Q-table to find the best action. If the table doesn't have enough information, the agent explores new actions to gather data. As the agent learns, the Q-table gets updated with more accurate q-values. This process creates a learned q-table that helps the agent make better decisions.
For example, in a maze-solving task, the Q-table might store values for actions like "move forward," "turn left," or "turn right" in different states. Initially, the table might have random values. After several attempts, the learned q-table will show higher values for actions that lead to the exit.
The Q-table is essential for q-learning because it allows the agent to store and retrieve information efficiently. Without it, the agent would struggle to remember past experiences and improve its behavior.
How Q-Learning Works
States, actions, and rewards in Q-learning
In Q-learning, states, actions, and rewards form the foundation of the learning process. A state represents the current situation the agent faces. Actions are the choices available to the agent in that state. Rewards are the feedback the agent receives after taking an action.
For example:
- In a grid maze, the agent learns to reach an exit worth 10 points. Actions leading to faster exits receive higher values.
- The agent interacts with states and actions, aiming to maximize total rewards.
- Boarding a train illustrates how different strategies impact total boarding times, showing how exploration affects rewards.
By focusing on states, actions, and rewards, Q-learning helps the agent make decisions that maximize future rewards.
Step-by-step process of the Q-learning algorithm
The Q-learning algorithm follows a structured process to teach the agent optimal decision-making:
- Initialization: Start with a Q-table where all Q-values are set to zero.
- Exploration: Choose an action using the ϵ-greedy policy, balancing exploration and exploitation.
- Action and Update: Take the action, observe the next state, and receive a reward. Update the Q-value using the Temporal Difference (TD) update rule.
- Iteration: Repeat the process across multiple episodes until the agent learns the best policy.
This step-by-step approach ensures the agent gradually improves its decision-making by learning from rewards and refining its Q-table.
Exploration vs. exploitation in learning
In Q-learning, you face a trade-off between exploration and exploitation. Exploration involves trying new actions to discover better rewards. Exploitation focuses on using known actions to maximize rewards based on the current Q-table.
Studies highlight this balance:
| Study | Findings |
|-------|----------|
| Chang et al. 2022 | Scarcity reduces resource-maximizing decisions. |
| Lloyd et al. 2022 | Childhood adversity limits exploration in tasks. |
| Lenow et al. 2017 | Stress increases exploitation in decision-making. |
| van Dooren et al. 2021 | Arousal boosts exploration; positive emotions enhance exploitation. |
The Cognitive Consistency framework suggests aligning exploration strategies with existing knowledge structures. This approach improves efficiency and performance in reinforcement learning tasks.
Balancing exploration and exploitation is key to optimizing rewards in Q-learning. By exploring wisely, you help the agent uncover better strategies while exploiting known actions to achieve consistent results.
Q-Learning in Machine Vision Systems

Applications in Adaptive Visual Tracking
A q-learning machine vision system can revolutionize adaptive visual tracking by enabling systems to adjust dynamically to changing environments. Visual tracking involves following an object as it moves through a scene. Traditional methods often struggle when objects change appearance or when lighting conditions vary. Q-learning addresses these challenges by learning from rewards and adapting its strategy over time.
For example, in a tracking task, the system receives a reward when it successfully predicts the object's location. If the prediction is incorrect, the system adjusts its approach to improve future accuracy. This iterative process ensures the system becomes more reliable in real-world applications.
Performance metrics highlight the effectiveness of q-learning in adaptive tracking. Below is a comparison of precision and success rates before and after applying q-learning-based trackers:
| Tracker | Precision Before | Precision After | Success Rate Before | Success Rate After |
|---|---|---|---|---|
| SiamCAR | 88.0% | 71.9% | 67.3% | 53.3% |
| TransT | 87.4% | 60.8% | 67.8% | 46.4% |
Another algorithm, AKCF, demonstrates varying success rates across different scenarios:
| Algorithm | Success Rate (%) |
|---|---|
| AKCF | 57.0 |
| AKCF | 65.9 |
| AKCF | 52.9 |
| AKCF | 52.5 |
| AKCF | 54.5 |
| AKCF | 57.5 |
| AKCF | 70.6 |
| AKCF | 67.5 |
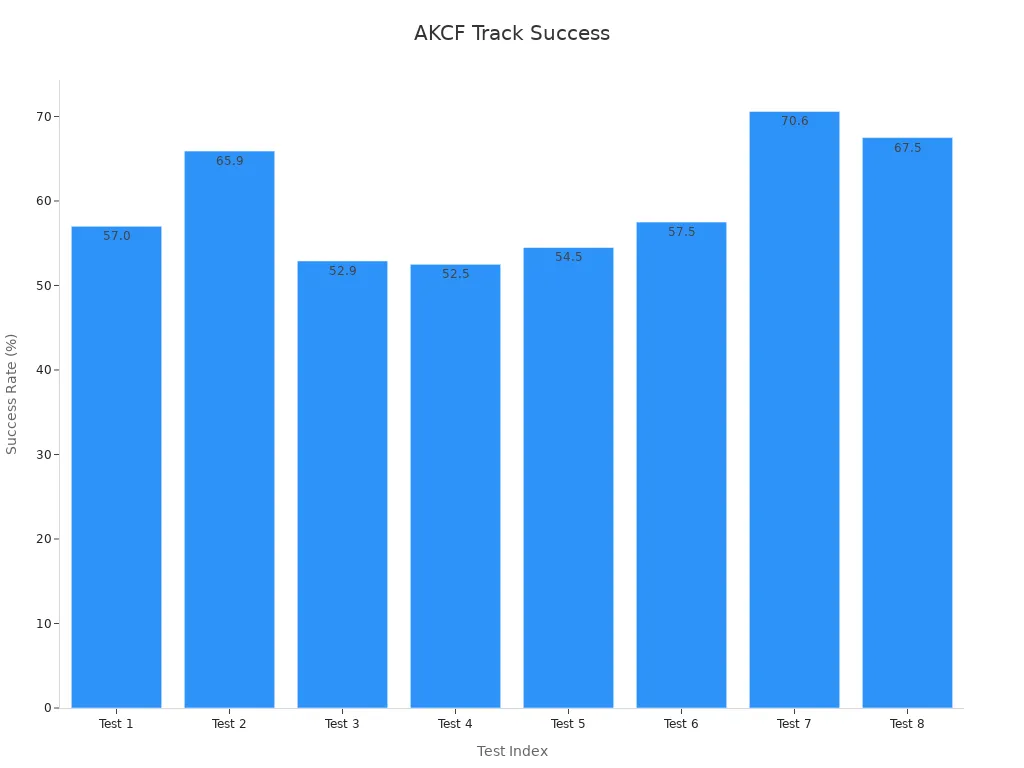
These results demonstrate how q-learning enhances tracking performance, making it a valuable tool for applications like surveillance and autonomous vehicles.
Path Planning for Mobile Robots
Path planning is another area where a q-learning machine vision system excels. Mobile robots rely on path planning to navigate environments efficiently and safely. Q-learning helps robots learn optimal paths by rewarding them for reaching their destination while avoiding obstacles.
Several metrics evaluate the effectiveness of q-learning in path planning:
- Path planning success rate measures how often the robot successfully plans a route across different terrains.
- Travel success rate ensures the robot reaches its goal without falling or colliding with obstacles.
- Planned path length assesses the distance covered during navigation.
- Planning time evaluates how quickly the robot generates a path.
In addition to these, security metrics measure the robot's distance from obstacles, ensuring safe navigation. Dimensional metrics focus on creating optimal trajectories, while smoothness metrics evaluate the energy and time spent on decision-making. These metrics highlight how q-learning optimizes both safety and efficiency in robotic navigation.
For instance, a robot navigating a cluttered warehouse might initially take inefficient routes. Over time, q-learning enables it to identify shorter, safer paths, reducing travel time and energy consumption. This adaptability makes q-learning indispensable for real-world applications in robotics.
Challenges in Machine Vision Tasks
Despite its advantages, a q-learning machine vision system faces several challenges. One major issue is the quality of data. Machine learning models, including q-learning, require high-quality visual data to perform effectively. Poor lighting, occlusions, or noisy images can degrade performance.
Another challenge lies in the complexity of certain tasks. For example, clinical applications often involve intricate visual data, such as medical imaging. These tasks demand tailored algorithms to address specific challenges, such as detecting anomalies or segmenting tissues accurately.
Lastly, q-learning systems must balance computational efficiency with accuracy. Real-time applications, like autonomous driving, require quick decision-making. However, achieving this speed without compromising accuracy remains a significant hurdle.
Addressing these challenges requires continuous advancements in machine learning techniques and hardware capabilities. By overcoming these limitations, q-learning can unlock its full potential in machine vision systems.
Practical Example: Implementing Q-Learning with Gymnasium

Overview of Gymnasium as a tool
Gymnasium is a powerful tool for building and testing reinforcement learning environments. It provides a wide range of pre-built environments where you can train agents to solve tasks. These environments simulate real-world scenarios, making them ideal for experimenting with q-learning. Gymnasium's flexibility allows you to customize environments to suit specific needs, such as vision-based tasks.
You can think of Gymnasium as a playground for reinforcement learning. It offers a controlled space where agents can interact with their surroundings, take actions, and receive feedback in the form of rewards. This feedback loop helps agents learn and improve over time.
Setting up a Q-learning environment
To set up a q-learning environment in Gymnasium, you need to follow a few steps. First, install Gymnasium and choose an environment that matches your task. For vision-based tasks, environments like "CartPole" or "MountainCar" can serve as good starting points. Next, initialize the Q-table, which will store the state-action values.
Once the environment is ready, you can define success metrics to evaluate the agent's performance. These metrics include:
| Metric | Description |
|---|---|
| success_once | Whether the task was successful at any point in the episode. |
| success_at_end | Whether the task was successful at the final step of the episode. |
| fail_once | Whether the task failed at any point in the episode. |
| fail_at_end | Whether the task failed at the final step of the episode. |
| return | The total reward accumulated over the course of the episode. |
These metrics help you track the agent's progress and identify areas for improvement.
Training an agent for vision-based tasks
Training an agent involves running multiple episodes where the agent interacts with the environment. During each episode, the agent explores different actions and updates the Q-table based on the rewards received. Over time, the agent learns to choose actions that maximize the total reward.
For example, in a vision-based task like object tracking, the agent might receive a reward for correctly identifying the object's position. If the agent makes an incorrect prediction, it adjusts its strategy to improve accuracy in future attempts. This iterative process ensures the agent becomes more effective at solving the task.
By using Gymnasium, you can create a structured environment to train agents and measure their performance. This approach makes q-learning accessible and practical for real-world applications.
Future of Q-Learning in Machine Vision
Emerging trends in reinforcement learning
Reinforcement learning continues to evolve, driven by advancements in technology and research. You can expect several exciting trends to shape the future of q-learning techniques:
- Scalability and Efficiency: New models will handle larger environments and reduce training time. Improved computational resources and algorithm designs will make this possible.
- Integration with Deep Learning: Deep Q Networks (DQN) exemplify how deep learning and reinforcement learning work together. This integration will lead to more powerful and adaptable systems.
- Explainability and Robustness: Researchers aim to create models that are easier to understand and more reliable. This is especially important for applications where safety matters.
- Ethical and Fair AI: Future systems will prioritize fairness and accountability. Ethical considerations will ensure autonomous systems make responsible decisions.
These trends highlight how q-learning will become more efficient, transparent, and ethical, paving the way for broader adoption in machine vision tasks.
Potential applications in robotics and healthcare
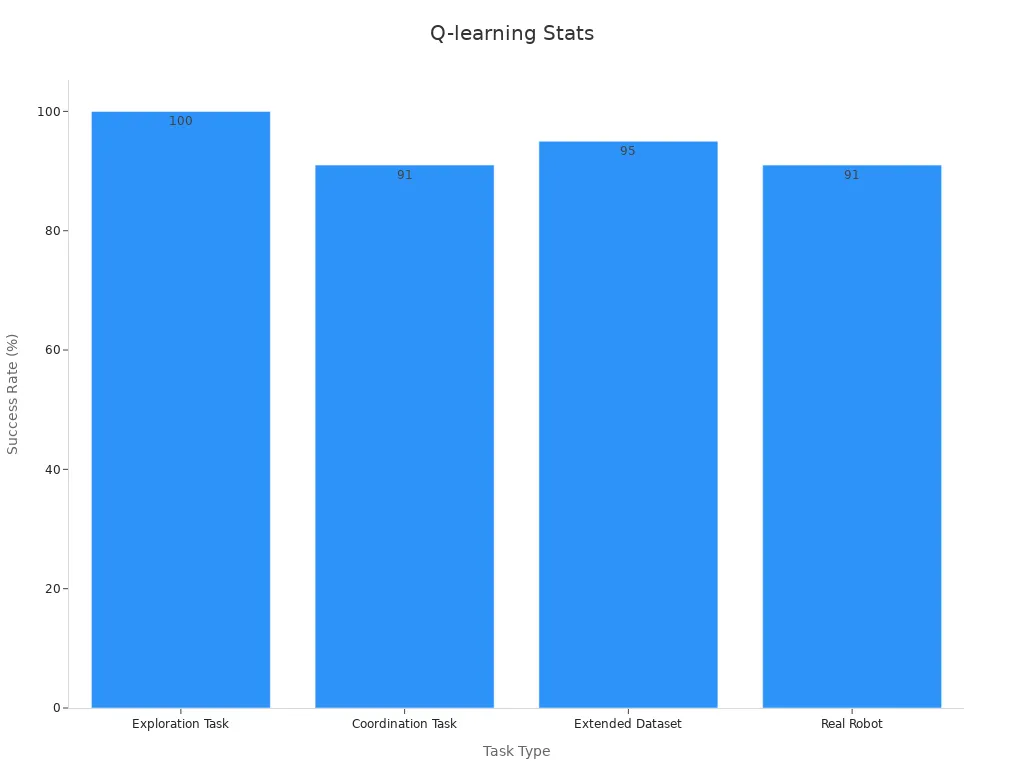
Q-learning has immense potential in robotics and healthcare. Robots can use q-learning to explore environments, coordinate tasks, and adapt to new challenges. For example, exploration tasks achieve a 100% success rate with fewer than two motions on average. Coordination tasks show a 91% success rate, demonstrating the reliability of q-learning in complex scenarios.
| Task Type | Success Rate (SR) | Average Motion Number (MN) |
|---|---|---|
| Exploration Task | 100% | < 2 |
| Coordination Task | 91% | 3.2 |
| Extended Dataset | 95% | 2 |
| Real Robot | 91% | 7.3 |
In healthcare, q-learning can assist in medical imaging and diagnostics. Systems trained with q-learning can identify anomalies in scans or optimize treatment plans. These applications improve accuracy and efficiency, benefiting both patients and practitioners.
Advancing AI-driven vision systems
AI-driven vision systems will become smarter and more adaptable with q-learning. You can expect these systems to handle dynamic environments better, making them ideal for tasks like surveillance and autonomous navigation. By learning from rewards, these systems will refine their strategies and improve decision-making.
For example, a surveillance system can use q-learning to track objects in crowded spaces. It adjusts its approach based on feedback, ensuring accurate tracking even in challenging conditions. Similarly, autonomous vehicles can navigate complex roads by learning optimal paths and avoiding obstacles.
As q-learning advances, AI-driven vision systems will become more reliable and versatile. This progress will open doors to innovative applications across industries, from transportation to security.
Q-learning plays a vital role in machine vision systems. It helps you create intelligent systems that adapt to dynamic environments and make smarter decisions. By learning from rewards, these systems improve their ability to interpret visual data and solve complex tasks like object tracking and path planning.
🧠 Tip: Q-learning isn't just theoretical. Tools like Gymnasium let you experiment with reinforcement learning in practical scenarios. You can train agents to tackle vision-based challenges and see the results firsthand.
Explore Q-learning and its applications. You’ll discover how it can transform industries like robotics, healthcare, and transportation.
FAQ
What is Q-learning in simple terms?
Q-learning is a type of machine learning where an agent learns by trying actions and receiving rewards. It uses a table, called the Q-table, to remember which actions work best in different situations. Over time, it improves its decisions to maximize rewards.
How does Q-learning help in machine vision?
Q-learning helps systems make better decisions in visual tasks. For example, it can improve object tracking or help robots navigate by learning from visual data. It adapts to changes in the environment, making it useful for dynamic tasks like surveillance or autonomous driving.
What is the role of the Q-table?
The Q-table stores the agent's knowledge about which actions lead to the best rewards in specific situations. It acts like a memory bank, helping the agent choose the best action based on past experiences.
Can Q-learning be used with deep learning?
Yes! Q-learning can combine with deep learning to handle complex tasks. This combination, called Deep Q-Learning, uses neural networks to estimate Q-values, making it possible to solve problems with large state and action spaces.
Is Q-learning suitable for real-time applications?
Q-learning can work in real-time, but it requires optimization. Faster algorithms and better hardware can help meet the speed and accuracy demands of real-time tasks like autonomous navigation or video analysis.
See Also
Understanding Transfer Learning's Role in Machine Vision
An Overview of Few-Shot and Active Learning Methods
Fundamentals of Sorting Systems in Machine Vision